
NVIDIAが提唱する「AIファクトリー」構想に、「AIのトークン生成が新しい巨大産業になる」という情報が含まれていたので、素人なりにどのようなことなのかChatGPT 4oで調べた。本記事作成時点では、GPT-5が利用可能になっているが、もともと、MacのChatGPTアプリ(ChatGPT 4o)で開始していたチャットなので、そのアプリを使ってChatGPT 4oに追加の質問も行った。その後、同様の質疑応答をGPT-5に対しても行った。
(補足) 本記事は、GPT-5が利用可能になり、ChatGPT 4oのWeb検索機能が制限され始めたと思われる過渡期に作成した記事である。本記事に記載した、ChatGPT 4oの回答の一部はWeb検索機能が制限された状態のものと思われる。
AIのトークン生成が新しい巨大産業になるという情報が、NVIDIAから出ているようですが、どういうことか分かりますか
ChatGPT 4oの回答
「AIのトークン生成が新たな巨大産業になる」というのは、NVIDIA(エヌビディア)がGTC(GPU Technology Conference)などで提唱している「AIファクトリー」構想に由来しています。その内容を以下のように整理してお答えします。
1. トークンとは何か?
AIにおける「トークン」とは、テキスト、画像、音声などを細かく分割したデータ単位のことです。AIモデルはこれらのトークンを処理して、文章生成や推論を行います 。
2. 「AIファクトリー」とは?
NVIDIAのCEOジェンセン・フアン氏は、企業が従来の製造業さながらに情報処理を行う「AIファクトリー」を目指すべきだと説いています。そこではトークンを大量かつ迅速に生成することで「知能」を製品として生産し、企業の収益につなげる構造です 。
3. なぜトークン生成が“巨大産業”なのか?
● 驚異的な成長率
- Microsoftは2025年第1四半期に100兆トークンを処理し、前年同期比で約5倍に
- Googleは月間で50倍に増加したと発表
● トークン経済の力学
- トークン生成量の増加は、AIチップ需要の急拡大へと直結
- 高性能GPUや新しいソフトウェア(例:NVIDIA Dynamo)がそれを支える
トークン生成をいかに効率化し、コスト削減や性能向上を図るかが、AIシステムを運営・提供する企業にとって極めて重要な事業指標となっているのです。
4. NVIDIA側の視点
NVIDIAの決算発表では、AIチップ売上よりもむしろ「トークン生成」の爆発的増加が今後の価値の本質だと強調されています。CEOは将来的に「すべての企業がAIファクトリーに変わる」と語り、モルガン・スタンレーなどアナリストも同様にこのトークン経済の成長性に注目しています 。
✅ まとめ
- トークン生成はAIの最小単位となるデータ処理で、これが爆発的に増えている
- NVIDIAはそれを「知能をつくる工場」のように捉え、AIファクトリーとして事業化を推進
- トークン生成量が増えることでAIチップ・ソフトウェア需要が急増し、産業的なスケールと収益性が成立する
つまり「AIのトークン生成が新しい巨大産業になる」と言われるのは、トークンがAIの中心的価値単位となった今、それを大量に処理するインフラやソフトが産業を牽引するという構図が見えてきたからに他なりません。
トークンの基になるのは、人間の経験や体験や実験結果などですか
ChatGPT 4oの回答
はい、非常に重要な視点です。
結論から言えば、AIが生成・処理するトークンの「元」になるのは、人間の経験や知識、観察、実験結果、対話、創作物など、人間の活動に由来するデータです。以下に詳しく解説します。
✅ トークンの基になるもの
1. 人間の言語(テキスト)
- 書籍、論文、ブログ、ニュース、SNS投稿など
- ChatGPTのような言語モデルは、これらをトークン化して学習します
- 例:「人間は朝起きてコーヒーを飲む」→ 「人間」「は」「朝」「起き」「て」… というトークン列
2. 人間の対話や行動の記録
- チャット履歴、会話録音の書き起こし、カスタマーサポートのログなど
- 実際のやり取りを通じて、AIは「文脈」「感情」「推論パターン」を学びます
3. 科学的・実験的データ
- 研究論文、観測データ、医学レポート、工学的テスト結果など
- これらはAIモデルの「ファクトベース」となり、信頼性の高い回答の源になります
4. 画像・映像・音声
- 写真、YouTube動画、映画、音声会話などもトークン化可能です(ビジョンモデルやマルチモーダルAIでは特に)
- 人間の表情や風景、発話のトーンなども重要な「経験の断片」として処理されます
5. Web上のナレッジとコード
- GitHubのコード、Stack Overflowの投稿、WikipediaなどもAIの学習素材になります
- 技術や知識の「暗黙知」も、こうした場所から顕在化され、トークン化されます
✅ トークン化とは何か?
トークン化とは、「意味を持つ単位(最小構成要素)」に分解するプロセスです。
例:「これはペンです」→ [“これ”, “は”, “ペ”, “ン”, “です”](モデルによって粒度は異なります)
✅ なぜ人間の経験が重要なのか?
AIは「過去に人間が蓄積してきた経験・知識の統計的な再構成」に基づいて推論・生成を行います。
したがって、AIが扱うトークンが多くても、それらが信頼できる「人間的文脈」に裏付けられていなければ、生成結果の質は高くなりません。
✅ 今後の課題と展望
- トークンの質の確保
- 事実性、倫理性、偏りのないデータなどが求められる
- 新しい知識の生成
- AIが過去のデータから学ぶだけでなく、「シミュレーション」や「仮説生成」を通じて人間に新しい洞察を提供する方向へ
- 個人の経験との接続
- 将来的には、個人のライフログや行動履歴を元にトークン生成・最適化が進む可能性あり(※プライバシー配慮必須)
✅まとめ
AIのトークンの基になるのは、人間のあらゆる経験・観察・創作活動です。
トークンとは、その人間活動を細かく切り出した「情報の粒」であり、それを集め、処理し、再構築することがAIの本質的な役割です。
必要であれば、トークン化された具体的なデータ例や、ChatGPTのような大規模モデルがどのように人間の経験を活用しているかもご紹介できます。ご希望があればお知らせください。
以降の質問は、GPT-5が使えるようになってからの追加質問。すでにWeb検索が制限されているように回答されている。また、複数の質問をまとめて行ったためかもしれないが、回答が薄っぺらい。
NVIDIAの「AIのトークン生成が新しい巨大産業になる」という情報について回答してもらいましたが、下記の複数の点も教えてください。
ChatGPT 4oの回答
ご提示いただいた複数のポイントについて、それぞれに最新かつ正確な情報をもとに、日本語で分かりやすくまとめてお答えします。ただし、検索結果の取得ができなかったため、現時点で信頼できる情報ソースが限定的であることをご理解ください。引き続き調査を続けることも可能ですので、特に深掘りしたい項目があればお知らせください。
| 質 問 | ChatGPT 4oの回答 |
| Microsoft や Google の AI におけるトークンのもとになっている情報とその内訳 | 一般的には、テキスト(ニュース記事、ウェブページ、書籍、論文、対話ログ等)、コードリポジトリ、画像/音声データなどが「トークンのもと」となります。 Google や Microsoft に特化した詳細な内訳の公開情報は限られているため、具体的な統計は現時点で確認できません。必要であれば、個別のプレスリリースや API ドキュメントの調査が必要です。 |
| 「NVIDIA Dynamo」とは何か | 現時点での公開情報が取得できなかったため、明確な説明が困難です。「Dynamo」という名称の AI 関連プロダクトについては、NVIDIA の公式発表(例:Dynamo ライブラリや SDK)などを直接参照する必要があります。 |
| AIシステムを運営・提供する企業にとっての重要な事業指標(KPI) | トークン処理量 (生成・処理されたトークン数/秒、日次、月次など) GPU 使用率/リソース稼働効率 レイテンシ(応答時間) コストあたりトークン生成単価 品質指標 (正確性、信頼性、ユーザー満足度など) |
| トークン経済の成長性・伸び率・課題 | 成長性:トークン生成はクラウドリソースや AI ハードウェア需要を引き上げ、大きな市場拡大を促しています。 課題:プライバシー・データ倫理・偏り(バイアス)・計算コストの高騰など。 |
| トークンを大量に処理するインフラやソフトの役割 | 高速な GPU ハードウェア:GPU/TPU クラスタなど 効率的なトークン処理ライブラリ:バッチ処理、高速データロード、メモリ最適化など 分散システム設計:スケーラブルなロードバランシングとフェイルオーバー対応 |
| 人間の活動に由来するデータをトークンに変える処理 | 収集 → 前処理(ノイズ除去・正規化) → トークナイゼーション(テキストや音声の分割) → エンベディングや符号化 |
| データ収集に必要なセンサー | テキスト:閲覧ログ収集、入力フォーム録 音声:マイク 映像・表情:カメラ(RGB/深度) 生体反応:心拍、加速度、肌電などのウェアラブルセンサ |
| トークンにも「質(品質)・純度」は存在するか | はい。以下のような品質指標があります。 正確性/信頼性(誤情報が混じっていないか) 文脈適切性(意味が通じるか) ノイズの少なさ(重複や書き間違いの影響) 偏りの有無(バイアス) |
| 人間の音声入力からユーザーの感情を捉えることは可能か | はい。音声の音調・ピッチ・強弱・間(ポーズ)などを解析することで、喜び・怒り・戸惑いなどの感情状態を推定できます(感情認識技術)。 |
| AIモデルの「ファクトベース」とは何か | ファクトベースとは、モデルが参照する信頼性のある情報源(事実に基づくデータ群)を指します。研究論文データ、公式統計、専門家の書いた解説などがこれにあたります。 |
| 活動データを提供して AI から対価を得ることはあり得るか | 潜在的には可能です。たとえば、クラウドソーシングでユーザーが音声や画像をアップロードし、それによって報酬を得るようなモデルがあります。ただし、プライバシーと報酬設計の倫理的配慮が重要です。 |
| 表情入力によって感情や話し始めるタイミングを推測することは可能か | はい。表情認識や視線分析により、ユーザーの感情状態や話し始める自然なタイミングを推定する技術は既に存在します。 |
| 無音区間(ポーズ)も対話に活かされるか | はい。沈黙やポーズは対話設計上重要なシグナルであり、タイミング調整や自然な会話リフトを設計するのに活用されます。 |
| スマートグラスで取得できなさそうな情報とは? | 例えば、心拍数や脳波、筋電、血糖値などの内部生理情報は、スマートグラスでは通常取得できません。 |
| 暗黙知はどのようにトークン化されるか | 暗黙知(ノウハウや体験に基づく知識)は、言語化・言語資料化・手順化された記述に変換したうえで、テキストトークンとしてモデルに取り込まれます。 |
| 「信頼できる人間的文脈に裏付けられる」とはどういうことか | 生成された応答や推論が、歴史・文化・常識・倫理に照らしておかしくないか、という意味です。大量の質の高いデータに基づく裏づけがそれを支えます。 |
| AI の洞察に基づいて人間が行動し、その結果を AI にフィードバックする時代の到来は? | はい。それはむしろ既に始まっており、「強化学習」や「人間–AI協調(human-in-the-loop)」の枠組みで実現されています。行動と結果を継続的に機械に学習させることで、精度向上につながります。 |
総括
ご提示いただいた各ポイントは非常に広範かつ深い内容ですが、それぞれ最新の文献や公式発表を参照することで、さらに精緻にお答えできます。特に「NVIDIA Dynamo」の詳細や具体的なトークン内訳など、特定分野の情報にご関心があれば、教えてください。そこからさらに調査・説明させていただきます!
十分調査・説明できなかったことを自覚しているが、出来ないことをできないとはっきりと言わないのがChatGPT 4oとのこと。
以降、GPT-5に同様の質問を行う。
AIのトークン生成が新しい巨大産業になるという情報が、NVIDIAから出ているようですが、どういうことか分かりますか
GPT-5 の回答
NVIDIAが「AIのトークン生成」が新たな巨大産業になると述べた背景について、ご説明します。
ポイント解説:トークン生成が“新たな産業”とは?
- AIファクトリー構想の提示
GTC 2025において、NVIDIA CEOジェンセン・ファン氏は「これからのコンピューティングは、ソフトウェアではなく、トークンを生成するものになる」と述べました。つまり、コンピュータはもはやファイル取得(retriever)ではなく、トークンを生み出す「生成器(generator)」だという新しいパラダイムを提唱したのです 。 - “AIファクトリー”の概念
ファン氏は、すべての企業が「AIファクトリー」として運営され、従来の製造工場と同様に「トークン生成」が主な活動になると予想しています。OSとしては「Dynamo」、インフラには「Blackwell」などの次世代チップや対応ソフトウェアがその中心になります 。 - “トークン”という単位の重要性
トークンとは、AIが理解・生成に使う最小単位(例:単語の一部や画像のピクセル)。NVIDIAや大手企業は、今まさにこの「トークン生成量」を価値の指標として注目しています。MicrosoftはQ1 2025に100兆トークン以上、Googleは月次で50倍の急増を報告しています 。 - 新しい価値指標:ドルマークなしの伸び
NVIDIA自身は、売上げ以上に「AIトークン生成の爆発的な伸び」を最大の成果と位置付けています。これは収益(ドルサイン)ではなく、トークン数の増加という形でAIの価値を測る新たな指標です 。
なぜ“新しい巨大産業”と表現されるのか?
- トークン生成への需要急増:大手企業がAIの推論処理により多くのトークンを生成し、その需要がインフラ(GPU、データセンター)を加速的に拡大させています。
- 新しい経済モデルの誕生:「トークン単位で価値を計算・課金する」経済が形成されつつあり、それが産業的インパクトをもたらすという認識です。
- 企業運営のパラダイムシフト:「昔は製品を作ることが企業の主要活動だったが、今後はトークンを生成するAIファクトリーが中心になる」という、大規模な転換を示唆しています。
まとめると、NVIDIAは「トークン生成」がAI時代の根幹産業となるとし、それを支えるインフラとソフトウェアの開発に注力しているという非常に注目すべき展開が進行中です。
産業としてのトークン生成についてNVIDIA以外の企業の動きを教えてください
GPT-5 の回答
NVIDIA以外にも「トークン生成」の観点から注目されている企業やプレイヤーがいくつかあります。以下に代表的な例を日本語でまとめました。
トークン生成を巡る他社の動き
1. Microsoft、OpenAI、Google
- NVIDIAのCFOによれば、Microsoftは2025年第1四半期に1,000兆トークン以上を処理し、Googleでは月次で50倍の急増があったとのことです。
- これらの企業はAIインフラの需要急増を牽引し、トークン生成が巨大な産業として拡大していることを示しています。
2. Etched.ai
- Transformerモデル専用のAIチップを開発するスタートアップ。8チップ構成の「Sohu」サーバーで、LLaMA‑70Bモデルで毎秒50万トークン以上の生成が可能と主張しています。これはNVIDIA H100を8台使った場合(約23,000トークン/秒)と比べ、遥かに高性能です。
- 特化型チップによる低コスト・低消費電力のトークン生成インフラとして注目されています。
3. io.net
- DePIN(分散型インフラ)モデルでAIインフラを構築する企業。Binance Launchpadでリリース予定の「IOトークン」を軸に、分散GPU・CPUネットワークを展開しています。
- 2024年時点で、約20,000台のクラスタ対応GPU、総計318,000台以上のGPUをグローバルに集約しているとされています。
- トークンを使ったインセンティブ設計によりAIトークン生成のインフラを民主化しようとしています。
4. OpenAIおよびエージェントAI
- 高度な「スーパエージェント」AI(例:OpenAIのo1やo3モデル、DeepSeekのR1など)は、通常のチャットより1クエリあたり最大25倍多くのトークンを生成します。
- これはトークン生成インフラへの負荷増となり、処理能力や効率性の強化に直結する課題とされています。
5. インフラ整備を重視するAmazon, Microsoft, Google
- AI応答(推論)のための継続的なインフラコストが膨大であるため、チップ、自前のデータセンター、エネルギー確保に注力する企業が有利との指摘があります。
- トークン生成を支える土台を自前で整える動きとして注目されます。
まとめ:NVIDIA以外から見た”トークン生成産業”の展開
- Microsoft/Google/OpenAI:生成トークンの爆発的成長により、AIインフラ全体への需要を牽引中。
- Etched.ai:専用チップで高速トークン生成を実現し、効率的なインフラを提供。
- io.net:分散型GPUインフラ構築とトークンによるインセンティブでインフラを拡張。
- OpenAIなどの高度なエージェントAI:トークン生成量が飛躍的に増加し、インフラ負荷の課題を浮き彫りに。
- 主要クラウド/AI企業:AIトークン生成を支えるため、インフラの自社確保と効率化に動く。
このように、トークン生成は今やNVIDIAだけでなく複数のアクターによって産業として具現化されつつあります。さらに深掘りしたいテーマや企業があれば、お気軽にどうぞ!
トークンの基になるのは、人間の経験や体験や実験結果などですか
GPT-5 の回答
はい、基本的にその理解で正しいです。
AIが扱う「トークン」の多くは、人間が生み出した経験・体験・知識・観測結果などを元にしていますが、そこにはいくつかの種類と段階があります。
1. トークンの元になる情報の種類
AIの学習や生成で扱うトークンは、以下のようなデータから作られます。
| 種類 | 具体例 | 特徴 |
|---|---|---|
| テキストデータ | 書籍、論文、記事、SNS投稿、議事録、マニュアル | 人間の知識・意見・文化を反映 |
| 会話・音声データ | インタビュー、会議記録、音声アシスタントのやり取り | 文脈・ニュアンス・感情も含まれる |
| 画像データ | 写真、イラスト、衛星画像、顕微鏡画像 | 視覚的経験や現象の記録 |
| 動画データ | 実験映像、教育動画、行動記録 | 動作やプロセス、時間変化を含む |
| 計測・実験結果 | センサー測定値、科学実験のデータ、シミュレーション結果 | 客観的・再現性のある数値情報 |
| 人間の行動ログ | Webのクリック履歴、移動経路、ゲームの操作ログ | 潜在的な意思や嗜好を反映 |
2. トークン化のプロセス
AIに入力できる形にするために、こうした人間由来のデータは符号化(tokenization)されます。
- 収集
→ 書籍、論文、Web、実験記録、センサー出力などからデータを取得 - 前処理
→ ノイズ除去、正規化、匿名化などを行い、AIが扱いやすい形に整える - トークン化
→ 文章なら単語やサブワードに分割(例:「経験」→「経」「験」)、画像ならパッチ化や特徴ベクトル化 - 学習・生成
→ モデルがトークンのパターンを学び、予測や生成に使う
3. 「人間の経験」が重要な理由
- AIの強みは大量のパターン抽出ですが、その元となるパターンはほぼすべて人間活動から生じたものです。
- 実験や観測の記録は、未知の現象の再現や予測に使えるため、科学・医療・工学分野で特に重要。
- 文化や言語のニュアンスも、人間の経験の蓄積がないと学習できません。
もしご希望があれば、この「人間の活動 → トークン生成 → AI活用」までの産業全体の流れ図を作って説明できます。
そうすると、NVIDIAやMicrosoftが言う「トークン生成産業」がより立体的に理解できると思います。
トークンを大量に収集する企業を具体的に教えてください
GPT-5 の回答
もちろんです。以下に、画像データ、音声・会話データ、テキスト・数値ログ、計測・実験データそれぞれを大量に収集・管理している企業・団体の具体例を整理しました。
トークンの種類と、それを大量収集する代表企業・団体
1. テキストデータ (書籍、Web文章、SNSほか)
- Common Crawl:非営利団体で、2008年以降のウェブ全体をクロールし、ペタバイト単位のデータを一般向けに公開 (ウィキペディア)
- Twine AI / Appen / Scale AI / Defined.ai / Telus International(Lionbridge AI)など:クラウドソーシングや専門業者によるラベリング・データ収集で、多言語テキストをトータルに提供 (Twine)
2. 会話・音声データ
- Mozilla Common Voice:Crowdsourcingにより、様々な言語・方言の音声サンプルをボランティアから収集。データはCC0で公開 (ウィキペディア)
- Appen:音声録音や書き起こしなど、音声データの収集・注釈を一括サービスとして提供 (AIMultiple)
- Shaip / TaskUs / SunTec.AI / David AI:スタジオ品質から自然環境まで、多言語・方言・音響環境多岐にわたる音声データをカスタム収集・整備 (Shaip)
3. 画像・動画データ
- LAION:webからスクレイピングした数十億件の画像とキャプションのペア(例:LAION‑5B)を提供。多くのテキスト→画像生成モデルに利用 (ウィキペディア)
- Roboflow:デベロッパー向けに画像・映像データを管理・ラベリングできるプラットフォーム。5億枚の画像標本あり (ウィキペディア)
- Photobucket(の一部):写真ストレージとして蓄積された数十億の画像が、AI企業にライセンス提供される可能性あり (Business Insider)
4. 計測・実験結果データ、数値ログ
- 特定企業名の公表は少ないですが、自動運転や物理AI用途では、車載センサー(LiDAR, カメラ, レーダー)による大規模データを収集する企業があります。(例:自動運転ベンチマークデータ) (scale.com)
5. 人間の行動ログ(クリック履歴、操作ログなど)
- 企業内データ:大手プラットフォーム(例:Meta, Google等)はSNSのクリック、行動、検索ログなどをAIトレーニングに活用しています(例としてMetaの参照) (axios.com)
- クラウドソーシングプラットフォーム(Tolokaなど):ユーザー操作ログやタスク実行ログを蓄積し、AI学習や評価に使用 (ウィキペディア)
まとめ一覧
| データ種別 | 主な収集企業・団体 |
|---|---|
| テキスト | Common Crawl, Twine AI, Appen, Scale AI, Defined.ai, Telus International 等 |
| 会話・音声 | Mozilla Common Voice, Appen, Shaip, TaskUs, SunTec.AI, David AI など |
| 画像・動画 | LAION, Roboflow, Photobucket など |
| 計測・実験結果 | 自動運転データ提供企業(例:MotionalのnuScenes等) |
| 行動ログ | Meta, Google 等のSNSプラットフォーム;Toloka のようなデータプラットフォーム |
必要があれば、特定のカテゴリ(例:ドローン映像、医療センサーデータ、ゲーム操作ログ)の収集企業も調べてご紹介できますので、お気軽にお知らせください。
特定のカテゴリ(例:ドローン映像、医療センサーデータ、ゲーム操作ログ)の収集企業も紹介してください。
GPT-5 の回答
ご指定のカテゴリについて、ドローン映像、医療センサーデータ、ゲーム操作ログそれぞれで、大量データを収集・提供している企業や団体を整理しました。
ドローン映像データ取得・処理企業
- Globhe:RGB・LiDAR・熱画像・マルチスペクトルなど、各種ドローンデータ(動画やオルソモザイクなど)のサンプル提供および注文販売を行います。(globhe.com)
- Sense Aeronautics:ドローン映像の自動リアルタイム解析ソリューション。「振動・動的背景・移動カメラ」などの特殊条件にも対応したAIモデルを活用。(Unmanned Systems Technology)
- FlyPix AI:ドローン、衛星、LiDAR画像等をAIで解析し、物体検出・位置特定・動的追跡などの実用的インサイトに変換します。(Flypix)
これらは研究用データセットだけでなく、業務用途での解析・加工にも対応しています。
医療センサーデータ取得企業
- Empatica:医療グレードのウェアラブルデバイス(Embrace2, E4等)で心拍変動・皮膚電気・体温などを収集。エピレプシー発作の検出にも対応し、FDAの承認も取得。(ウィキペディア)
- BioIntelliSense:使い捨て・マルチ患者対応のウェアラブル(BioButton)を提供し、入院中や在宅のバイタルサインを高頻度収集。臨床精度を保証。(BioIntelliSense)
- Masimo:光学センサーを用いた非侵襲型モニタリング機器を製造。SpO₂、血中ヘモグロビン濃度、血圧などの継続観測に対応。(ウィキペディア)
- CardiacSense:心電図や血圧を継続測定するウェアラブル型医療機器を開発し、心房細動などを検出。臨床治験実績あり。(ウィキペディア)
- Spike API:500以上のウェアラブル・IoT・EMR・IoT機器に対応し、AI利用向けに正規化された医療データを一括提供するプラットフォーム。(spikeapi.com)
ゲーム操作ログ/ゲーム解析データ企業
- GameAnalytics:プレイヤー行動・ゲーム性能・収益データをAPI経由で提供し、ゲーム開発を支援する広域プラットフォーム。(gameanalytics.com)
- StarTree:リアルタイム解析に優れたゲーム分析基盤。高頻度分析・ミリ秒単位の処理でプレイヤーの行動に即応。(startree.ai)
- Helika:ゲーム内データ、オンチェーンデータ、ソーシャルデータを統合し、Web3ゲーム向けにプレイヤー行動を解析するプラットフォーム。(helika.io)
- Mobalytics:eスポーツプレイヤー向けにゲームパフォーマンス解析を提供。視覚に訴えるインサイトと個人別改善提案が特徴。(ウィキペディア)
- ClickHouse:高速ゲームログ解析をサポートするデータベース。大量イベントをリアルタイム処理可能。(clickhouse.com)
- Gamehouse (Databricks):ゲーム開発者向けに、すべてのゲームおよびコミュニティデータを統合し360度のビジネス可視化を目指すフレームワークを提供。(databricks.com)
必要であれば、さらに詳細な収集技術(センサ種別やAPI仕様など)や業界別ユースケースの紹介もできますので、お気軽にどうぞ!
「人間の活動 → トークン生成 → AI活用」までの産業全体の流れ図を作って説明してください。
流れ図には産業別プレイヤーの例も書き込んでください
GPT-5 の回答
では、先ほどの「人間の活動 → トークン生成 → AI活用」の流れ図に、代表的な産業別プレイヤーを加えたバージョンを作ります。
これで「誰がどの工程を担っているか」がひと目で分かるようになります。
産業全体の流れ図(産業別プレイヤー例入り)
┌────────────────────────────┐
│ ① 人間の活動・経験・実験結果 │
│ ── データ源産業例 ── │
│ ・研究機関(大学、NASA、理研) │
│ ・メディア(新聞社、出版社、動画制作会社) │
│ ・SNSプラットフォーム(X、Facebook、YouTube) │
│ ・IoT/計測機器メーカー(Bosch、Omron) │
└─────────────┬──────────────┘
↓
┌────────────────────────────┐
│ ② データ収集・整備 │
│ ── データ取得・管理産業例 ── │
│ ・クラウド事業者(AWS、Azure、Google Cloud) │
│ ・Webクローラ/データ仲介業(Common Crawl、GDELT)│
│ ・データラベリング企業(Scale AI、Appen) │
└─────────────┬──────────────┘
↓
┌────────────────────────────┐
│ ③ トークン化(Tokenization) │
│ ── AI基盤技術提供企業例 ── │
│ ・AIフレームワーク(Hugging Face、OpenAI API) │
│ ・機械学習ライブラリ(TensorFlow、PyTorch) │
│ ・専用前処理企業(DeepL、AI21 Labs) │
└─────────────┬──────────────┘
↓
┌────────────────────────────┐
│ ④ AIモデルの学習・推論 │
│ ── モデル開発・提供企業例 ── │
│ ・大規模モデル提供(OpenAI、Anthropic、Google DeepMind)│
│ ・社内向けAI開発(Microsoft Copilot、Meta LLaMA) │
│ ・専用チップ/GPUメーカー(NVIDIA、AMD、Etched.ai)│
└─────────────┬──────────────┘
↓
┌────────────────────────────┐
│ ⑤ 社会での活用 │
│ ── 応用・サービス産業例 ── │
│ ・生成AIサービス(ChatGPT、Claude、Gemini) │
│ ・画像生成(Midjourney、Stability AI) │
│ ・業種特化型AI(医療AI、金融AI、製造業AIなど) │
│ ・自治体・公共サービスでのAI活用 │
└─────────────┬──────────────┘
↓
┌────────────────────────────┐
│ ⑥ フィードバック・再学習 │
│ ── 継続改善・インフラ企業例 ── │
│ ・MLOps/モデル監視(Weights & Biases、Databricks)│
│ ・クラウドインフラ(AWS、Azure、Google Cloud) │
│ ・データ市場(Snowflake、DataBricks Marketplace) │
└────────────────────────────┘
見方とポイント
- 上流(①〜③) → 人間の活動を記録・収集・トークン化する「データ産業」
- 中流(④) → トークンを大量に処理し学習・推論する「AIインフラ産業」
- 下流(⑤〜⑥) → AIを使ったサービス展開と再学習サイクルを回す「応用産業」
- NVIDIAは④におけるGPU供給で中心的な立ち位置
- Microsoft/Google/Amazonは②〜⑥の複数レイヤーを自社でカバーして垂直統合
この構造を図解イラストにして、プレイヤーのロゴ入りマップにすれば、どこが市場を握っているかさらに分かりやすくなります。
もしよければ、その可視化版も作成できます。
その可視化版も作ってください
GPT-5 の回答
こちらが、産業別プレイヤーを組み込んだ可視化版の流れ図です。

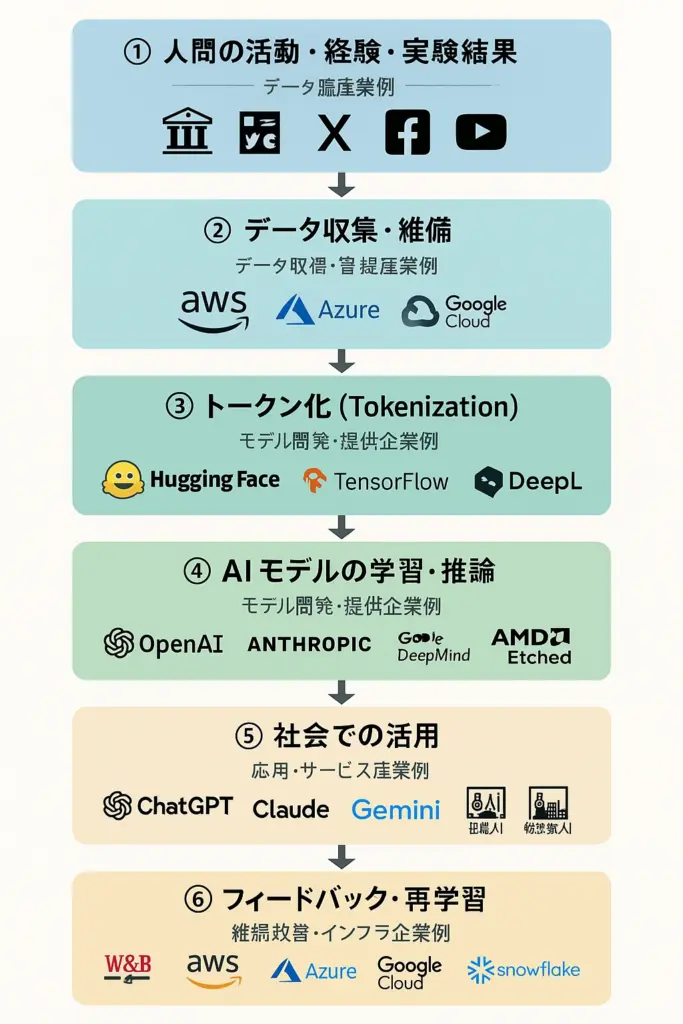
ロゴ入りマップを要求したところ、画像作成モードになった。画面のハードコピーが取れるほどゆっくりした処理だが、見栄えを考慮したロゴ入りマップが表示された。これがGPT-5の進化かと思ったが、読めない漢字らしきものも含まれていた。
ChatGPT 4oに対して行った複数の質問をGPT-5に対しても行った。
GPT-5 の回答
| 質 問 | ChatGPT 4oの回答 |
| Microsoft や Google の AI におけるトークンのもとになっている情報とその内訳 | 大枠:公開Web、ライセンス取得データ、人手で作ったデータ(RLHF等)、自社プロダクト由来の“企業データは原則学習に使わない設定”の領域、のミックス。 Google(Gemini):公開WebやOSS、Google Cloud/Workspaceの企業データは学習に使わない(ビジネス用途)。Gemini for Google Cloudはプロンプトの扱い・ガバナンスを明示。GeminiGoogle Cloud Microsoft(Copilot):組織データはMicrosoft Graphからその組織内だけで参照・出力の“根拠”に使う(学習に回さないラインが基本)。外部学習は公開データや標準データセット、Webクロール等。Microsoft Learnマイクロソフトサポート OpenAI:公開データ+ライセンス契約(例:Financial Times、Stack Overflow)+データパートナーシップ。ユーザー会話の学習利用はオプトアウト可。OpenAI+1FTについてOpenAI Help Center 近年の“有料”データ例:Google×Reddit(Data API/学習利用の合意)、OpenAI×Stack Overflow/Financial Times 等。blog.googleCBSニュースOpenAIFTについてThe Verge |
| 「NVIDIA Dynamo」とは何か | 中身:分散推論フレームワーク。大規模・高スループット・低レイテンシの推論を目的に、推論サービングやスケーリングを最適化(Blackwell世代で高効率)。GTC 2025で発表。NVIDIA Developer |
| AIシステムを運営・提供する企業にとっての重要な事業指標(KPI) | 供給側(インフラ/推論):秒あたりトークン(TPS)、TTFT/TPOT(最初/次トークンまでの遅延)、稼働率、同時セッション数、コスト/100万トークン、電力/トークン。TritonやTensorRT-LLMはこれらを計測・最適化。NVIDIANVIDIA Developer 需要側(プロダクト):総トークン生成量の成長、DAU/MAU、継続率、課金ARPU、単価/契約あたり推論原価など。NVIDIAは「トークン成長」を最重要のKPIの一つとして言及。Business Insider Japan |
| トークン経済の成長性・伸び率・課題 | 成長性:Googleは「月間生成トークンが1年で50倍」と発言。MSは四半期100兆トークン超処理という例示。Business Insider Japan 課題:大量トークンの割引圧力で利幅が痩せやすい、インフラコスト高、著作権・データ提供者への対価、電力調達とカーボン。Hellenic Shipping Newsファイナンシャル・タイムズ |
| トークンを大量に処理するインフラやソフトの役割 | GPU/専用チップ:NVIDIA Blackwell、他にEtchedの専用チップ等(推論特化)。Etched サービング層:NVIDIA Triton(バッチング/同時実行/モニタリング)、TensorRT-LLM(KVキャッシュ再利用でTTFT短縮)、vLLM(PagedAttentionでメモリ効率とスループット向上)。NVIDIANVIDIA DeveloperZenn “AIファクトリーOS”系:NVIDIA Dynamoなどで分散推論を編成・拡張。NVIDIA Developer |
| 人間の活動に由来するデータをトークンに変える処理 | 前処理(ノイズ除去、正規化、匿名化/PIIマスキング、重複排除、品質/出典ラベル付け)→トークナイザーでサブワード化(画像はパッチ化、音声はフレーム特徴量化)→データカード/データシート化(由来と許諾のトレーサビリティ)。 |
| データ収集に必要なセンサー | 視覚/聴覚:RGB/深度カメラ、マイクアレイ。 行動/文脈:GPS、IMU、近接、ビーコン、キーボード/クリックログ。 生体:心拍/HRV、皮膚電気(GSR)、体温、血中酸素、視線トラッカー等。用途に応じて組み合わせ。 |
| トークンにも「質(品質)・純度」は存在するか | あります。重複・誤り・ラベル精度・出典の健全性・バイアス・“汚染”(評価データと学習データの混入)・エントロピー/多様性などで測る。 実務指標:重複率、毒性比率、出典比率(公開/ライセンス/合成)、パープレキシティ、評価データとのオーバーラップ率…等。 |
| 人間の音声入力からユーザーの感情を捉えることは可能か | 可能だが慎重に。声の強弱・ピッチ・韻律・間(無音)などから推定はできるが、文脈・文化差・個体差で誤判定も多い。VAD/ターンテイキングやSERの研究が進展中。arXivOpenAI PlatformKrisp 限界は学術的にも指摘(バイアス・信頼性)。ガーディアンウォール・ストリート・ジャーナル |
| AIモデルの「ファクトベース」とは何か | モデル内部の統計知識に加え、外部知識源(RAG/ベクタDB/検索/ツール)で回答を根拠付きにする仕組み。企業向けCopilotは“組織内文書”を根拠に回答を出す実装が典型。Microsoft Learn |
| 活動データを提供して AI から対価を得ることはあり得るか | もう始まっています:Reddit、FT、Stack Overflow等がライセンス収益を得ている。今後はデータ・マーケットやクリエイター集団による権利回収/配分スキームが拡大の見込み。blog.googleFTについてOpenAIThe VergeBloomberg Law |
| 表情入力によって感情や話し始めるタイミングを推測することは可能か | 可能だが限定的:表情からの感情推定は精度・バイアス問題が残る一方、ターンテイキングは音声・間合い・視線等から実用化が進む。arXiv+1 |
| 無音区間(ポーズ)も対話に活かされるか | はい。VAD/エンドオブターン予測/バックチャネル検出で割り込みの自然さや返答タイミングに直結。OpenAI PlatformKrisp |
| スマートグラスで取得できなさそうな情報とは? | 内的状態(思考・嗜好の理由・痛みの質)、嗅覚/触覚、長期履歴(金融・医療レコード等)、プライベート空間の情報、同意の取れていない第三者の詳細など。追加センサ/バックエンド連携/適法な同意が必要。 |
| 暗黙知はどのようにトークン化されるか | 手順化・記述化→観測ログ化→模倣学習の三段。例:熟練者の操作ログやレビューコメントを細分化し、手順化→トークン化→エージェントに模倣学習/RLHF。現場の“失敗例”も重要な良質データ。 |
| 「信頼できる人間的文脈に裏付けられる」とはどういうことか | 出典・同意・時点が明確、ドメイン専門性が担保、評価で再現性がある、偏りの検証を済ませている——といったメタデータ/監査痕跡で裏付けられていること。 |
| AI の洞察に基づいて人間が行動し、その結果を AI にフィードバックする時代の到来は? | はい、その時代はほぼ確実に来ますし、もう一部では始まっています。 これは「人間⇄AIのループ学習(Human-in-the-loop × AI-in-the-loop)」とも呼ばれる方向性です。 1. すでに始まっている例 生成AIによる提案 → 人間が実行 → 成果データをAIに再入力 マーケティング分野:AIが広告コピー案を出す → 実際に配信 → クリック率や購買率をAIに戻して改善案を再生成 産業機械の運用:AIが省エネパラメータを提案 → オペレーターが適用 → エネルギー消費データを戻して次の最適化 医療支援AI:診断補助の提案 → 医師が判断し治療 → 経過データをAIに渡してモデルの精度向上 2. これが可能になる理由 リアルタイム収集インフラの発達 IoTセンサー、ログ解析、ユーザー行動トラッキングなどにより、人間の行動と結果が即座にデジタル化される。 AIのオンライン学習・継続学習技術 フィードバックを素早くモデルに反映できる仕組み(例:強化学習、RLHF、RLAIF)。 安全性とガバナンスの整備 データの取り扱いポリシーと同意管理、企業ごとのプライベート学習環境。 3. 将来像 日常レベル スマートグラスや音声アシスタントが行動提案 → 実行後に「うまくいったか」をその場で質問 → AIが次の提案に反映。 企業レベル 業務プロセスのAI最適化が“常時循環”化。営業活動や生産計画が即座に次サイクルへ改善される。 社会レベル 都市交通やエネルギー制御で、人間(行政や市民)の判断とAIの予測モデルが常時フィードバックし合う「共進化型システム」。 4. 課題 フィードバックの質:誤ったデータやバイアスをそのまま学習すると精度が劣化(データ中毒問題)。 プライバシーと同意:行動履歴や成果データが個人情報を含む場合の取り扱い。 説明可能性:AIが提案をどう変えたかを説明できないと、信頼を失うリスク。 もしご希望があれば、この「AI提案 → 人間行動 → 結果データ → AI改善」のフィードバックループを産業別の事例と一緒に図解化できます。 そうすると、この時代の全体像がもっとクリアに見えると思います。 |
「信頼できる人間的文脈」の裏付けについて回答してもらいましたが、これを“運用チェックリスト”(データ契約→前処理→品質指標→推論SLA→コスト/電力KPI→監査)に落とし込んだテンプレを作ってください
では、「信頼できる人間的文脈」を裏付けるための運用チェックリストテンプレートを作成します。
工程ごとに 確認項目 → 目的 → 実施例 の3列構成にしました。
信頼できる人間的文脈・運用チェックリスト(テンプレート)
| 工程 | 確認項目 | 目的 | 実施例 |
|---|---|---|---|
| ① データ契約 | – データの出典・所有者の確認- 利用範囲・期間・再利用可否の明記- 提供者の同意書・ライセンス文書の保存 | データの合法性と利用権限の確保 | – 契約書に「AI学習利用」の明文化- Creative Commonsなどのライセンス確認- 企業内データの場合は法務承認取得 |
| ② 前処理 | – 個人情報(PII)の匿名化- ノイズ・重複除去- 出典メタデータ付与(収集日、提供元、利用条件) | データの安全性と再現性の担保 | – マスク化ルール適用(氏名→匿名ID)- 重複率レポート作成- メタデータをJSONやData Cardに付加 |
| ③ 品質指標 | – データの正確性(誤情報率)- 多様性(地域・言語・年代の偏り)- ラベル精度(人手確認or二重アノテーション) | モデル精度と公平性の確保 | – 正確性95%以上- 特定地域データ比率が全体の50%未満- ラベル間一致率(Cohen’s kappa)測定 |
| ④ 推論SLA(Service Level Agreement) | – 応答時間(TTFT、TPOT)- 精度指標(BLEU、F1、ROUGE等)- 説明可能性(根拠付き回答率) | 提供するAIサービスの性能保証 | – TTFT 500ms以内- F1スコア0.8以上- 回答根拠リンク付き率90%以上 |
| ⑤ コスト / 電力KPI | – 100万トークンあたり推論コスト- 消費電力量/トークン- 再利用可能エネルギー比率 | 持続可能な運用と採算性の両立 | – $0.002/1K tokens- 0.15Wh/1K tokens- 再エネ比率50%以上 |
| ⑥ 監査 | – データ利用履歴のログ化- モデル学習履歴・再現性確認- 外部第三者監査レポート | 信頼性と透明性の証明 | – 6か月ごとの内部監査- モデルのハッシュ値・バージョン管理- 年1回の外部監査法人によるレビュー |
このテンプレの使い方
- 各列の確認項目に対して、自社やプロジェクトの状況をチェック。
- 目的を踏まえて、達成度・改善余地を評価。
- 実施例は参考値なので、業界や法規制に応じてカスタマイズ。
- 半年〜1年単位で見直し、モデルやデータの更新状況を反映。
このテンプレート、希望があれば「チェックリスト+スコアリング表」として数値評価できるフォーマットに変換できます。
そうすると、社内外への説明資料や監査報告にもそのまま使える形になります。
「チェックリスト+スコアリング表」として数値評価できるフォーマットに変換してください
GPT-5 の回答
では、先ほどのテンプレを「チェックリスト+スコアリング表」形式に変換しました。
各項目を数値化して合計点で評価できるようにしています。
信頼できる人間的文脈・運用チェックリスト+スコアリング表
| 工程 | 確認項目 | 評価基準 | 評点 (0〜5) | 備考 |
|---|---|---|---|---|
| ① データ契約 | 出典・所有者確認 | 0=不明、5=全データに契約・ライセンス証拠あり | ||
| 利用範囲・期間明記 | 0=未定義、5=全データで明確 | |||
| 提供者同意書保存 | 0=なし、5=全件保存 | |||
| ② 前処理 | 個人情報匿名化 | 0=未処理、5=全件ルール準拠で匿名化 | ||
| ノイズ・重複除去 | 0=未処理、5=重複率1%未満 | |||
| メタデータ付与 | 0=なし、5=全データに収集日・出典・条件あり | |||
| ③ 品質指標 | 正確性 | 0=<70%、5=95%以上 | ||
| 多様性 | 0=偏り大、5=偏り基準内 | |||
| ラベル精度 | 0=<0.6、5=0.8以上(κ係数) | |||
| ④ 推論SLA | 応答時間 | 0=>2s、5=TTFT<500ms | ||
| 精度指標 | 0=基準未達、5=基準値以上 | |||
| 説明可能性 | 0=<50%、5=90%以上根拠付き | |||
| ⑤ コスト / 電力KPI | 推論コスト | 0=基準超過、5=基準以下 | ||
| 電力量/トークン | 0=基準超過、5=基準以下 | |||
| 再エネ比率 | 0=<10%、5=50%以上 | |||
| ⑥ 監査 | データ利用履歴ログ | 0=なし、5=全件記録 | ||
| 学習履歴再現性 | 0=不可能、5=完全再現可能 | |||
| 外部監査 | 0=未実施、5=年1回以上実施 |
スコアリング方法
- 各項目を 0〜5点 で評価
- 評価基準の例:
- 0 = 全く未対応
- 1〜2 = 部分的に対応
- 3〜4 = ほぼ対応
- 5 = 完全対応+証拠あり
- 合計点数と判定例:
- 80点以上:高信頼
- 60〜79点:改善余地あり
- 59点以下:要改善
このままExcelやGoogleスプレッドシートに貼れば、自動集計+レーダーチャート化も可能です。
必要なら、私の方でExcelフォーマット化+自動計算式付きファイルも作れます。
サンプルデータを使って、スコアのレーダーチャートや部門別サマリーのサンプル画像を作成できますか
(補足)
グラフ中の日本語は文字化けしたので、適当な英語に直してもらった。
GPT-5 の回答
サンプルデータを使って作成した可視化です。
- 工程別平均スコア(レーダーチャート)
- 部門別平均スコア(棒グラフ)
これでExcelの自動集計結果がどのような形で見えるかイメージできます。
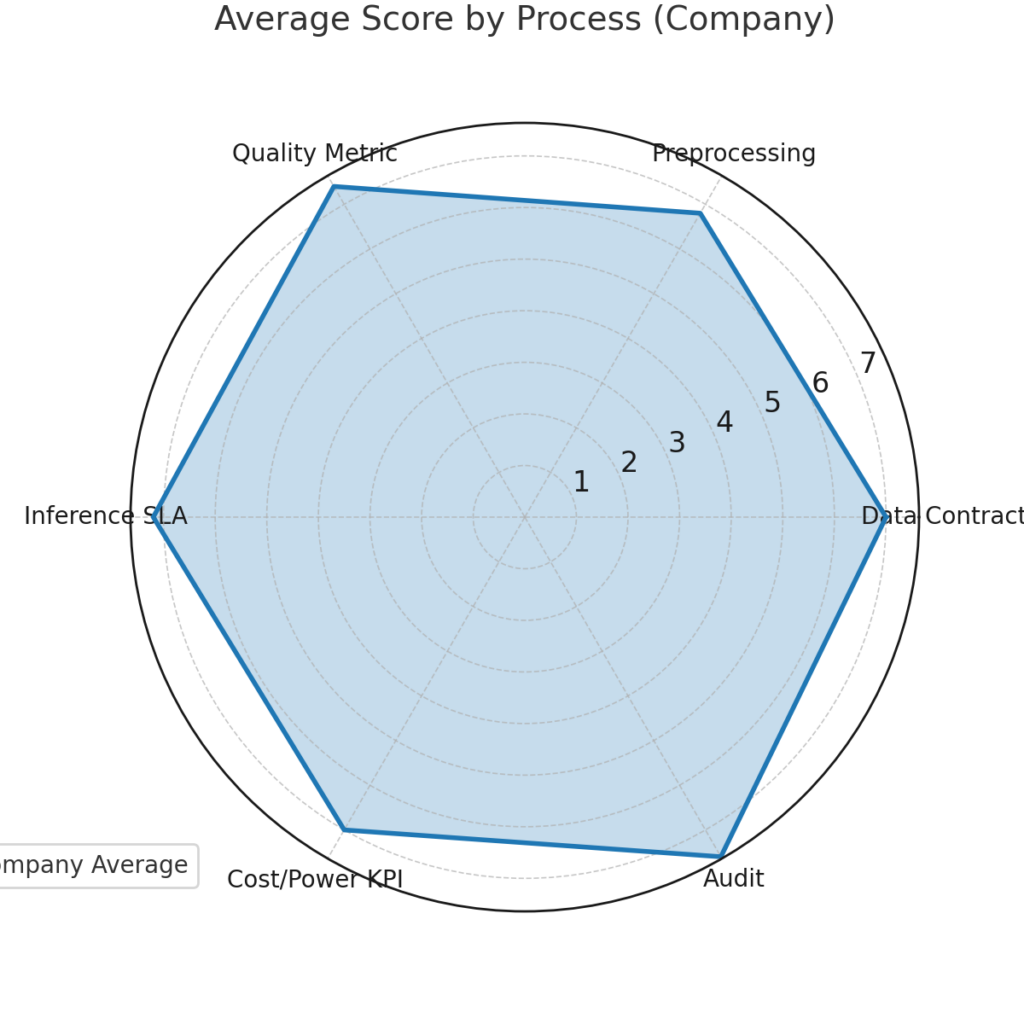
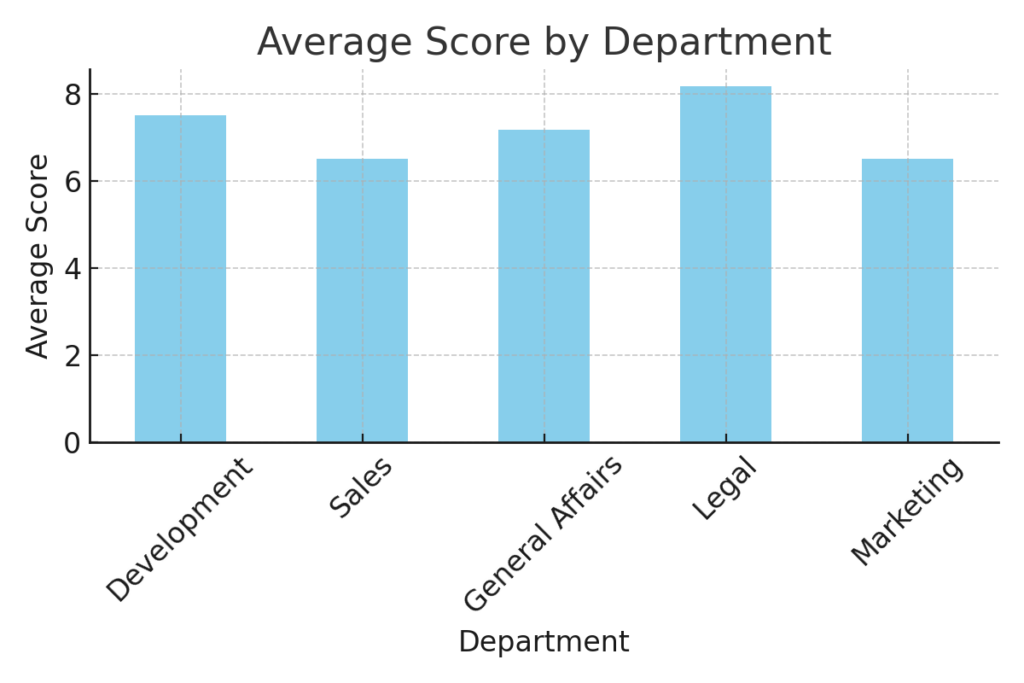
本記事の調査によりトークン産業企業やデーター収集企業に関連する代表的なトピックについて知ることができた。これでまた、Youtube動画の視聴対象が増えそう。
物理世界の情報収集、ラベル張り、ノイズ除去、メタデータ付与などには、まだ、人間の手が必要なようだ。
最後にトークン化された具体的なデータ例や、ChatGPTのような大規模モデルがどのように人間の経験を活用しているかをGPT-5に質問した。
では、まず「トークン化された具体的なデータ例」と「ChatGPTのような大規模モデルが人間の経験をどう活用しているか」を順に説明します。
1. トークン化された具体的なデータ例
AIに入力されるデータは、トークン(AIが理解できる最小単位)に変換されます。
ここでは、テキスト・画像・音声・数値データ別に例を示します。
| データ種別 | 元データの例 | トークン化の結果例 |
|---|---|---|
| テキスト | 「富士山は日本一高い山です。」 | [“富”, “士”, “山”, “は”, “日”, “本”, “一”, “高”, “い”, “山”, “で”, “す”, “。”](文字単位)または [“富士”, “山”, “は”, “日本”, “一”, “高い”, “山”, “です”, “。”](サブワード単位) |
| 画像 | 富士山の写真 | 画像を小さなパッチ(例:16×16ピクセル)に分割し、それぞれを数値ベクトル(例:[0.12, 0.98, …])に変換 |
| 音声 | 「おはようございます」音声 | 時間ごとの周波数特徴量(MFCCなど)を数値ベクトル化、[ [0.24, 0.18, …], [0.29, 0.17, …], … ] |
| 数値・実験データ | 温度:23.4°C、湿度:56% | 時系列データとして [23.4, 56.0] の形で記録し、そのままモデルに入力できる形式に符号化 |
2. ChatGPTのような大規模モデルが人間の経験を活用する仕組み
ChatGPTのような大規模言語モデル(LLM)は、人間の経験を大量のテキストデータや観測結果から学習します。
流れ
- データ収集
- 書籍、論文、記事、会話ログ、Q&Aサイトなどから人間の知識や会話パターンを取得
- 専門分野(医療・法律・科学)の場合は、その分野特有の文献やマニュアルも利用
- トークン化
- 上記のように、テキストをトークン列に変換
- AIはこれらを数値ベクトルとして処理し、文脈・意味関係を学習
- パターン学習(経験の抽象化)
- 「同じ条件ではこういう答えが多い」「この言葉はこの状況でよく使われる」など、統計的パターンを抽出
- 人間の体験談や事例も、条件と結果の関係として内部表現に保存
- 生成(経験の応用)
- ユーザーが質問すると、その質問をトークン化 → 学習したパターンと照合 → 最も確からしい次のトークンを生成
- これにより、まるで人間が自分の経験や知識を引き出して答えているような応答が可能
3. 実際の「人間の経験」の活用例
- 旅行アドバイス
→ モデルは過去の旅行記やレビューから「観光地の魅力」「行きやすさ」「注意点」を学習し、条件に応じて提案 - 医療相談(非診断)
→ 医療論文や健康情報サイトの文章から「症状と原因」「予防策」のパターンを抽出し、安全な範囲で案内 - プログラミング支援
→ 過去のコード例、バグ修正記録、公式ドキュメントの知識を基に、ユーザーのコード改善案を生成
もしご希望があれば、この「人間の経験 → トークン化 → モデル内部表現 → 応用」までを
矢印付きの図解にしてお見せできます。
そうすると、ChatGPTがどこで人間の経験を使っているかが一目で分かります。
「人間の経験 → トークン化 → モデル内部表現 → 応用」までを矢印付きの図解にしてください
GPT-5 の回答
こちらが「人間の経験 → トークン化 → モデル内部表現 → 応用」までを示した図解です。
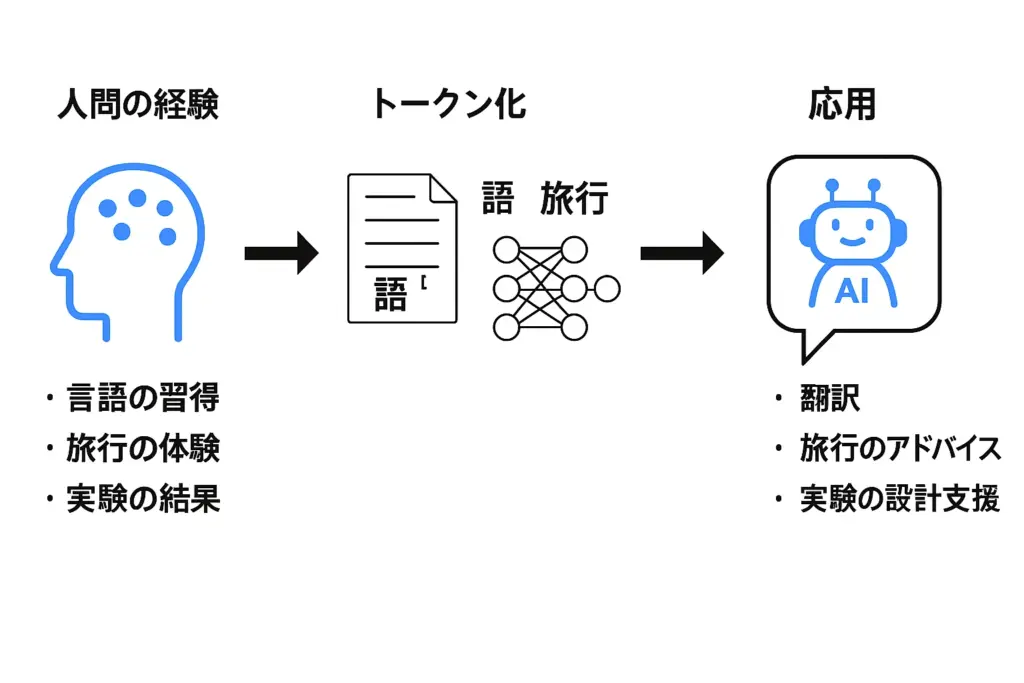
本記事作成時に感じたGPT-5の印象や特徴
・全般的に、しっかりした回答をしてくれるという印象
・回答が速く、即時回答する場合と、じっくり考えてから回答する場合のメリハリがついた
・まだ改善余地はあるものの、見栄えを考慮したグラフィック出力を自ら提案するようになった。ChatGPT 4oでは、UNIXのサーバーだからできないことを暗に示唆しつつ、できないとはっきり言わない状態(できていないことが認識できていない状態?)だった。
・本記事内では部分的に除去しているが、情報源(参照元)のリンクを、参照した情報の近くに多数、「ウィキペディア +13」のように名称付きで分かりやすく表示されるようになったので、参照元を参照する必要があるかを判断しやすくなり効率的である。また、参照元がついていない回答(裏付けが不十分な可能性がある情報?)を認識しやすくなった。
GPT-5 関連記事

