
下記の記事では、Codex処理の使用量として表示される入力トークン、キャッシュ入力、出力トークン、推論出力(reasoning tokens)から、API利用料の目安を計算する方法を整理した。

前回の式は、ざっくり言うと次のものだった。
費用 =
非キャッシュ入力 × 入力単価
+ キャッシュ入力 × キャッシュ入力単価
+ 出力トークン × 出力単価
※ 推論出力(reasoning tokens)は出力トークンに含まれるしかし、Web検索、画像入力、画像生成、画像編集、音声、Containerなどを使うと、通常のトークン料金とは「別枠」の料金が発生し、上記の式だけでは費用の算出には不十分であることが分かっていたので、今回は、それらの処理の単価表を単に眺める代わりに、私たちが実際にやりそうな作業を1つ題材にして、工程ごとの費用を積み上げてみることにした。
題材はこれである。
「Codexにブログ記事を1本書かせる」
(Web検索でネタを集め、本文を生成し、アイキャッチ画像を1枚作る)
この1本がいくらになるのか、実測値を貼り付けながら最後まで追いかけてみたい。
なお、本記事の内容は OpenAI API の従量課金の話であり、ChatGPT Plus / Pro や Codex のアプリ利用料金(サブスク料金)とは別の話である。また、料金は変わる可能性があり、この記事では実行時点の単価と、1 USD = 162円の概算で計算している。
Codexの処理にかかる費用を調べると、入出力トークン、キャッシュトークン、推論出力(reasoning tokens)があることが分かり、それらの単価から、1つの処理にかかった費用を算出しましたが、添付画像の通り、別料金が発生する場合があることも分かりました。どの程度の費用が発生するか、サンプル処理を行って費用の内訳を出せるように、まず、表の各種類のサンプル処理の実施要領(計画)を提案してください
以下の記事内容は上記質問をCodexに対して行い、計画の作成及びその計画に基づくサンプル処理を行なってもらって算出した金額を元にしたものである。
各サンプル処理の費用は、付録「実測データ一覧」として本記事に添付している。
(注)本記事の内容は正確性を保証するものではない。
(2026年6月30日 追記)YouTube動画を追加しました。 https://youtu.be/2-ahCi-NGL0
今回の「記事1本」ワークフロー
題材にしたワークフローは、次の5工程である。
(補足) モデル費とは上記記事で紹介した計算式で算出できる基本的な費用である。
| 工程 | 内容 | 関係する費用 |
|---|---|---|
| ① ネタ集め | Web検索を複数回 | モデル費 + 検索ツール費 |
| ② 構成・下書き | テキスト生成(標準) | モデル費 |
| ③ 推敲・仕上げ | テキスト生成(標準) | モデル費 |
| ④ アイキャッチ生成 | 横長画像を1枚生成 | 画像メディア費 |
| ⑤ 補足チェック | 軽いCSV集計などを Container で | Container費 + モデル費 |
このうち①〜③は「ふつうのテキスト処理」だが、④と⑤で別枠の料金が乗る。ここが前回の記事で紹介した式から漏れていた部分である。
各工程を、今回の実測値で順番に埋めていく。
ひとことメモ
④のアイキャッチや⑤のContainerは「やる人とやらない人がいる」工程である。自分のワークフローに無い工程は、その行ごと費用から外して読めばよい。記事を読みながら「自分はどの工程をやるか」をチェックしておくと、後半の合計が自分用の数字になる。
① ネタ集め:Web検索は「回数」で効く
Web検索は、通常のモデル使用料に加えて、検索ツールの呼び出し料金が別に乗る。
今回の単発測定では、Web検索1回 + 短い回答で約1.84円だった。
このうち検索ツール費だけで約1.62円である。つまり、出力が短くても検索回数が増えると費用が積み上がる。
記事1本のためにネタを集めるとなると、検索は1回では済まない。
仮に10回検索する構成にすると、検索ツール費だけで次のようになる。
| 項目 | 単価の目安 | 10回ぶん |
|---|---|---|
| 検索ツール費 | 約1.62円/回 | 約16.2円 |
| 回答生成のモデル費(短文×10回相当) | 約0.22円/回 | 約2.2円 |
| ①小計 | 約18.4円 |
検索の「中身」ではなく「回数」で増えるのがポイントである。
ひとことメモ
個人ブログのネタ集めなら、Codexに何度も検索させるより、自分でブラウザで数件読んでから「この情報をもとに書いて」と渡す方が安く済むことが多い。
検索を10回から3回に減らすだけで、ここの費用は約半分以下になる。Web検索は便利だが、回数は意識して絞りたい。
② 構成・下書き:標準テキスト処理
ここは前回の記事で紹介した式そのままの世界である。
約4,600入力トークンを渡して短い分類結果を返す、という共通テキスト処理を Standard で実行したところ、約3.84円だった。
実際の下書きは出力がもっと長くなるので、ここでは構成出し+下書きで標準処理を2〜3回まわすイメージとして、概算で約10円前後を見ておく。
| 項目 | 概算費用 |
|---|---|
| ②小計(標準処理×数回) | 約10円 |
ひとことメモ
ここで効くのがキャッシュ入力である。
同じ前提(ブログの方針、トーン、過去記事の要約など)を毎回渡すなら、その部分はキャッシュが効いて単価が下がる。
プロンプトの「変わらない部分」を先頭に固定しておくと、②の費用はじわじわ下がる。
前回記事のキャッシュの話が、ここで実益になる。
③ 推敲・仕上げ:ここでサービス階層を選ぶ
下書きを直す工程も標準テキスト処理だが、ここで Standard / Batch / Flex / Priority という「サービス階層」の選択が関係してくる。
同じ共通処理を4方式で比較した結果が次である。
(補足) デフォルトは「Standard」
| 方式 | 今回の概算費用 | Standard比 | 見方 |
|---|---|---|---|
| Standard | 約3.84円 | 1.00倍 | 通常処理 |
| Batch | 約1.92円 | 約0.50倍 | 非同期でよければ安い |
| Flex | 約0.33円 | 約0.087倍 | 今回はキャッシュが効いて非常に安かった |
| Priority | 約10.22円 | 約2.66倍 | 優先処理なので高い |
注意したいのは、プロンプトに「Priorityで実行してください」と書くだけでは切り替わらない点である。
API呼び出し側で指定する必要がある。
service_tier="priority" # Flexなら "flex"Batchはさらに別で、通常リクエストに指定するのではなく、Batch APIにジョブとして投入する方式である。
仕上げ工程は標準のまま、約4円ほどを見ておく。
| 項目 | 概算費用 |
|---|---|
| ③小計(Standard) | 約4円 |
ひとことメモ
個人ブログの記事生成に Priority は基本いらない。
Priorityは「ユーザーを待たせたくない本番サービス」向けで、単価がStandardの2.6倍にもなる。
自分のブログを自分のペースで書くだけなら、StandardかFlexで十分である。
むしろ「急がないからFlexでいいや」くらいの気持ちで回すと、③の費用は何分の一かになる。
④ アイキャッチ生成:サイズと品質で数円単位に
画像関連は、画像入力・画像生成・画像編集で費用の考え方が少し違う。
今回の単発測定では次のとおりだった。
| 処理 | 内容 | 概算費用 |
|---|---|---|
| 画像入力 | 512×512画像を短く解析 | 約0.37〜0.38円 |
| 画像生成 | 画像1枚生成 | 約0.97円 |
| 画像編集 | 生成画像を編集 | 約2.30円 |
そして、この記事用に実際に作った横長アイキャッチがこちらの条件である。
| 項目 | 内容 |
|---|---|
| モデル | gpt-image-2 |
| サイズ | 1536×1024 |
| 品質 | medium |
| 出力形式 | PNG |
| 枚数 | 1枚 |
| 概算費用 | $0.041975(約6.80円) |
低品質の小さな画像なら1円前後で済むこともあるが、ブログ用の横長アイキャッチのようにサイズと品質を上げると、数円程度になる。
| 項目 | 概算費用 |
|---|---|
| ④小計(横長アイキャッチ1枚) | 約6.80円 |
ひとことメモ
アイキャッチは「生成」より「編集」のほうが高くなりやすい(元画像・マスク・出力画像が全部関係するため)。気に入らなくて何度も編集で直すより、プロンプトを練って一発生成を狙うほうが安い。サイズも、本当に1536×1024が要るのか一度見直す価値がある。記事の見栄えと費用のバランスを取りたいところ。
⑤ 補足チェック:Containerは「固定費」が乗る
記事内で簡単な集計表やグラフを出したいとき、Container(Code Interpreter)を使うことがある。
今回、1GB Containerで小さなCSV集計+グラフ生成を行ったところ、約7.27円だった。
問題は、このうち約4.86円がContainerセッション費だという点である。
処理そのものが軽くても、セッションを立てた時点でこの固定費が乗る。
| 項目 | 概算費用 |
|---|---|
| Containerセッション費(固定) | 約4.86円 |
| 集計・グラフ生成のモデル費など | 約2.41円 |
| ⑤小計 | 約7.27円 |
ひとことメモ
Containerは「軽い処理でも固定費が乗る」のが曲者である。
記事1本のためだけに毎回立てるのはもったいない。
やるなら、その日にまとめたい集計を1セッションで片付けてしまうほうが効率がよい。
簡単な表計算くらいなら、わざわざContainerを使わず自分の手元(ExcelやNumbers)で済ませる選択肢も普通にアリである。
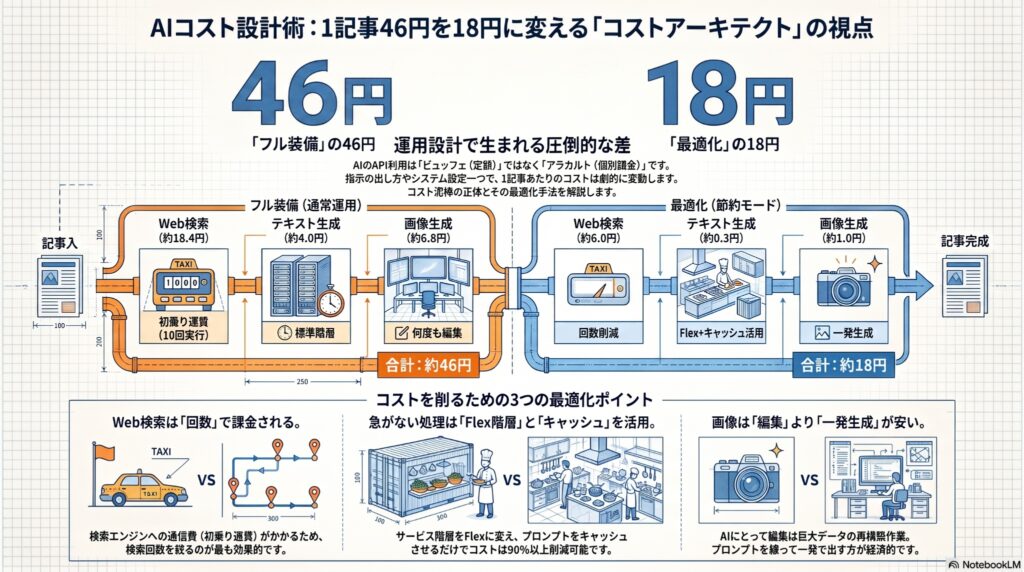
「記事1本」の合計を出してみる
ここまでの工程を積み上げると、フル装備(検索10回+アイキャッチ+Container)の場合は次のようになる。
| 工程 | 内容 | 概算費用 |
|---|---|---|
| ① ネタ集め | Web検索10回 + 短い回答 | 約18.4円 |
| ② 構成・下書き | 標準処理×数回 | 約10円 |
| ③ 推敲・仕上げ | 標準処理 | 約4円 |
| ④ アイキャッチ | 横長画像1枚生成 | 約6.80円 |
| ⑤ 補足チェック | Container集計 | 約7.27円 |
| 合計 | 約46円 |
記事1本あたり約46円。思ったより高いと感じるか、安いと感じるかは人それぞれだが、内訳を見ると「①Web検索」と「⑤Container」という別枠料金が、全体の半分以上を占めていることが分かる。
逆に言えば、ここを削れば一気に安くなる。
同じ記事を「節約モード」で書くと
では、追加料金が乗りやすい部分を意識して節約すると、どこまで下がるか。
| 工夫 | 変更後 |
|---|---|
| Web検索を10回→3回に絞る | ①が約18.4円→約6円 |
| 仕上げをFlexに | ③が約4円→1円未満 |
| アイキャッチを小さめ・低品質で1枚 | ④が約6.80円→約1円前後 |
| Containerを使わず手元で集計 | ⑤が約7.27円→0円 |
これらを全部適用すると、合計はおおよそ約18円前後まで下がる。フル装備の約46円と比べると、半額以下である。
つまり「記事1本いくらか」は固定ではなく、どの追加料金を使うかの設計しだいで2〜3倍変わる、というのが今回いちばん伝えたい点である。
ひとことメモ
全部を節約モードにする必要はない。「アイキャッチだけはきれいに出したい」なら④にお金をかけ、その代わり①の検索回数を削る、といったメリハリでいい。自分が記事の何にこだわるかで、お金をかける工程を選べばよい。
実装するなら:記録しておきたい項目
費用を後から振り返れるよう、各処理で次を記録しておくとよい。
(モデル費用)model
(サービス階層)service_tier
(入力トークン)input_tokens
(キャッシュトークン)cached_tokens
(出力トークン)output_tokens
(推論出力)reasoning_tokens
(以下、追加費用に関連する部分)
text/audio/image別トークン
web_search_call件数
container_id / memory_limit / セッション数
batchかどうか
エラー時にusageがあるかそして費用計算は、前回の式に追加項を足した「完全版」で考える。
総額 =
通常モデル費用 ← 前回の式
+ Web検索費 ← 検索回数 × 単価
+ 画像・音声などのメディア費 ← サイズ・品質・長さ
+ Container費 ← セッション固定費
(そのうえで Batch/Flex/Priority の単価に切り替える)単価は変わる可能性があるので、コードに直接書き込むより設定ファイル化しておくほうがよい。
ひとことメモ
ここまで記録しておくと、Home Assistantのダッシュボードに「今月のCodex記事制作費」を出す、といった可視化にそのまま使える。通常トークンだけでなく、検索回数やContainerセッション数も保存しておくのがコツである。次回、この可視化の作り方を扱いたい。
まとめ
「Codexに記事を1本書かせるといくらか」を、工程ごとに積み上げてみた結果、分かったのは次のことだった。
- フル装備(検索10回+アイキャッチ+Container)で約46円、節約モードで約18円前後
- 差を生むのは、通常トークンではなく「Web検索」「画像」「Container」という別枠料金
- Web検索は回数、画像はサイズ・品質、Containerはセッション固定費が効く
- サービス階層は、個人ブログ用途ならPriorityは基本不要、急がないならFlexで十分
- reasoning tokens は output tokens の内数なので、相変わらず二重加算しない
前回の記事が「基本の計算方法」だったのに対し、今回は「実際の作業に当てはめると、追加料金でいくら変わるか」を見た。
通常トークンだけ見ていると費用感を見誤る。
Web検索・画像・Container・サービス階層という4つの追加項目を意識するだけで、記事1本のコストは自分でコントロールできるようになる。
追加費用の目安について、おおよそ言及できたように思う。最初に、各処理のサンプル処理を行い、Web検索や画像生成などの単価を求めたが、それらのサンプル処理を一度に実施したので結構時間がかかり、トラブルも何度も発生した。また、5時間枠を2回リセットした。iPhoneのHOME AssistantのダッシュボードでCodexの5時間枠の使用パーセントをモニターしながら、80%程度に達した時点でリセットを行なった。5時間枠が3つたまっていたが、何に使おうかと考えていたところ、この記事のデータ作成に使用することができ時間を節約できた。
これまでに見たことがない下記のエラーメッセージが表示されることもあった。
Error running remote compact task: Selected model is at capacity. Please try a different model.
This model is not supported when using X-OpenAI-Internal-Codex-Responses-Lite.
付録:実測データ一覧
本文では「記事1本」のワークフローに沿って必要な数字だけを抜き出した。
ここでは、その元になった単発測定の全データを参考用にまとめておく。
本文に登場しなかった音声処理なども含む。
実測結果のまとめ(処理別)
成功した測定分の合計は $0.2178045(1 USD = 162円換算で約35.28円)だった。
| 処理 | 内容 | 概算費用 |
|---|---|---|
| Standardテキスト処理 | 約4,600入力トークン → 短い分類結果 | 約3.84円 |
| Batch | 同じ処理をBatchで実行 | 約1.92円 |
| Flex | 同じ処理。キャッシュが大きく効いた | 約0.33円 |
| Priority | 同じ入力を優先処理 | 約10.22円 |
| Web検索 | Web検索1回 + 短い回答 | 約1.84円 |
| 画像入力 | 512×512画像を短く解析 | 約0.37〜0.38円 |
| 画像生成 | 画像1枚生成 | 約0.97円 |
| 画像編集 | 生成画像を編集 | 約2.30円 |
| Realtime音声会話 | 約5秒音声入力 + 短い音声回答 | 約0.56円 |
| 音声文字起こし | 約10秒音声 | 約0.46円 |
| 音声翻訳 | 約10秒音声を英訳・音声生成 | 約0.92円 |
| Container | 1GB Containerで小CSV集計 + グラフ生成 | 約7.27円 |
短い画像・音声処理は思ったより低額だった一方で、ContainerやPriorityは小さな処理でも目立つ金額になった。
費用区分別の内訳
費用の性質で分けると、次のようになる。
| 費用区分 | 米ドル | 円換算 |
|---|---|---|
| 通常モデル費用 | $0.1456705 | 約23.60円 |
| Web検索ツール費 | $0.0100000 | 約1.62円 |
| 画像・音声メディア費 | $0.0321340 | 約5.21円 |
| Container費 | $0.0300000 | 約4.86円 |
| 合計 | $0.2178045 | 約35.28円 |
通常モデル費用が最大だが、Container費も無視できない。小さなCSV処理でも約4.86円のセッション費が乗っている。
サービス階層の比較
| 方式 | 概算費用 | Standard比 | 見方 |
|---|---|---|---|
| Standard | 約3.84円 | 1.00倍 | 通常処理 |
| Batch | 約1.92円 | 約0.50倍 | 非同期でよければ安い |
| Flex | 約0.33円 | 約0.087倍 | 今回はキャッシュが効いて非常に安かった |
| Priority | 約10.22円 | 約2.66倍 | 優先処理なので高い |
画像処理で効く因子
| 因子 | 費用への影響 |
|---|---|
| 画像サイズ | 大きいほど高くなりやすい |
detail | low より high / original の方が高くなりやすい |
quality | low < medium < high の順で高くなりやすい |
| 出力枚数 | 枚数に応じて増える |
| 参照画像・編集元画像 | 入力画像トークンとして関係する |
| ファイル形式 | 費用より通信量・保存容量への影響が中心 |
音声処理で効く因子と実測値(本文外)
本文の「記事を書く」工程には登場しないが、音声を扱う場合の参考に残しておく。音声は長さにほぼ比例する。
| 因子 | 費用への影響 |
|---|---|
| 入力音声の長さ | 長いほど増える |
| 出力音声の長さ | 長く話させるほど増える |
| 会話ターン数 | Realtimeでは履歴が増えやすい |
| 無音区間 | 入力に含めると課金対象になり得る |
| モデル | 文字起こし・翻訳・会話で単価が違う |
| ファイル形式 | 費用よりファイルサイズ・転送時間への影響が中心 |
| 処理 | 内容 | 概算費用 |
|---|---|---|
| Realtime音声会話 | 約5秒の音声入力 + 短い音声回答 | 約0.56円 |
| 音声文字起こし | 約10秒音声 | 約0.46円 |
| 音声翻訳 | 約10秒音声を英訳・音声生成 | 約0.92円 |
10秒では安くても、10分・1時間となると差が大きくなる。
Realtime会話ではターン数が増えると履歴が次の入力に含まれ、費用が増える可能性がある。
高くなりやすい / 安くしやすい処理
| 高くなりやすいもの | 理由 |
|---|---|
| Priority | 通常より高い優先処理単価になる |
| Container | 小さな処理でもセッション費が乗る |
| 画像編集 | 元画像・マスク・出力画像が関係する |
| Web検索を何度も使う処理 | 検索回数ごとの費用が積み上がる |
| 長い音声処理 | 秒数・分数に比例しやすい |
| 安くしやすいもの | 工夫 |
|---|---|
| 大量の非同期処理 | Batchを使う |
| 急がない処理 | Flexを検討する |
| 画像解析 | detail="low" から試す |
| 画像生成 | 小さめサイズ・低品質・1枚生成から試す |
| 音声処理 | 無音を削り、必要部分だけ処理する |
| Web検索 | 検索回数を必要最小限にする |
付録:Batch、Flex、Priorityについて
Batch / Flex / Priority は、プロンプト本文で指定するものではなく、APIの呼び出し方法・パラメータ・Project設定で決まるものです。
| 種類 | 何か | どう指定するか | 向いている処理 | 向いていない処理 | 課金・費用感 | 注意点 |
|---|---|---|---|---|---|---|
| Batch | 非同期のまとめ処理 | /v1/batches にJSONLファイルをアップロードしてBatchジョブを作る | 大量分類、評価、埋め込み作成、データ処理、夜間処理など | すぐ返答が必要なチャット、対話処理 | 同期APIより約50%安い | 完了は最大24時間枠。結果は後で取得する |
| Flex | 安いが遅め・不安定な同期処理 | APIリクエストで service_tier="flex" | 急がない単発処理、評価、データ整形、低優先度処理 | 本番の即時応答、失敗できない処理 | Batch API rates相当。キャッシュも効く | リソース不足時は 429 Resource Unavailable。その場合は課金なし |
| Priority | 速く安定させる優先処理 | APIリクエストで service_tier="priority"、またはProject設定 | ユーザー向け本番アプリ、低遅延が重要な処理 | 大量バッチ、評価、ETL、不規則な大量処理 | Standardより高いPriority単価 | 急激なトラフィック増加時はStandardへ降格される場合あり |
プロンプトで指定すれば適用されるのか
基本的には いいえ です。
例えばユーザーがプロンプトに、
この処理をPriorityで実行してくださいと書いても、それだけではAPIの service_tier は変わりません。
適用されるのは、API呼び出し側で明示的にこう指定した場合です。
client.responses.create(
model="gpt-5.5",
input="...",
service_tier="priority"
)またはFlexなら、
client.responses.create(
model="gpt-5.5",
input="...",
service_tier="flex"
)Batchはさらに別で、通常リクエストに service_tier="batch" と書く方式ではなく、Batch APIにジョブとして投入する方式です。
今回の測定結果に照らすと
同じ約4,600入力トークンの短い分類処理では、こうでした。
| 方式 | 今回の概算費用 | Standard比 | 解釈 |
|---|---|---|---|
| Standard | 約3.84円 | 1.00倍 | 通常処理 |
| Batch | 約1.92円 | 約0.50倍 | ほぼ半額 |
| Flex | 約0.33円 | 約0.087倍 | Flex単価+キャッシュ効果で非常に安い |
| Priority | 約10.22円 | 約2.66倍 | 速さ・安定性優先で高い |
Flexが極端に安く見えたのは、今回の測定では キャッシュ入力が大きく効いたためです。
常にこの比率になるとは限りません。
実務上の使い分け
| 目的 | 選ぶ候補 |
|---|---|
| 安く大量に処理したい、結果は後でよい | Batch |
| 多少遅くても安くしたい | Flex |
| ユーザーを待たせたくない、本番で低遅延が重要 | Priority |
| 普通のAPI利用 | Standard / default |
参照: Batch API, Flex processing, Priority processing
付録:画像関連の処理で費用に影響を与える因子
画像関連の費用は、大きく分けると 画像入力/解析 と 画像生成/編集 で効く因子が違います。
ざっくり言うと、費用に強く効くのは「画像サイズ」「detail」「品質 quality」「出力枚数」「参照画像の数」です。
一方、PNG/JPEG/WebPなどのファイル形式や圧縮率は、主に通信量・保存容量・速度に効き、画像トークン費用そのものへの影響は限定的です。
費用に影響する因子
| 因子 | 主に影響する処理 | 費用への影響 | 説明 |
|---|---|---|---|
| 画像の縦横サイズ | 画像入力、画像生成、画像編集 | 大 | 画像入力ではトークン化時のパッチ数・タイル数に影響します。画像生成では出力画像が大きいほど出力トークンが増えます。 |
detail | 画像入力・Vision解析 | 大 | low は低コスト。high や original は細部を見るためトークンが増えやすいです。 |
| モデル | 画像入力、画像生成、画像編集 | 大 | モデルごとに画像のリサイズ規則、トークン換算、単価が異なります。 |
| 画像枚数 | 画像入力、参照画像つき生成/編集 | 大 | 入力画像が増えると、基本的に画像入力トークンも増えます。 |
出力枚数 n | 画像生成 | 大 | 1枚より2枚、2枚より4枚のほうが概ね比例的に増えます。 |
生成品質 quality | 画像生成・編集 | 大 | low < medium < high の順に、出力トークン・処理時間が増えやすいです。 |
出力サイズ size | 画像生成・編集 | 大 | 1024×1024より、2K・4K系のほうが高くなります。 |
| 参照画像・編集元画像 | 画像編集、参照画像つき生成 | 大 | 編集では元画像・参照画像も入力画像として処理されるため、生成だけより高くなりやすいです。 |
input_fidelity | 画像編集・参照画像ワークフロー | 中〜大 | 入力画像の細部をどれだけ保持するかに関係します。ただし gpt-image-2 では変更不可で、高忠実度処理が自動です。 |
| テキストプロンプトの長さ | 画像生成・編集 | 小〜中 | 長い指示文はテキスト入力トークンとして加算されます。ただし画像出力費に比べると小さいことが多いです。 |
| ファイル形式 PNG/JPEG/WebP/GIF | 画像入力、画像生成出力 | 小 | 入力画像の課金は主にピクセル寸法・detail・モデルで決まります。形式そのものより、対応可否や通信量に効きます。 |
| JPEG/WebP圧縮率 | 画像生成出力 | 小 | 主にファイルサイズ・転送時間に影響します。モデルの画像生成トークン費用を直接大きく下げるものではありません。 |
| マスク画像 | 画像編集 | 中 | マスクは編集対象範囲を指定します。マスク自体の形式・サイズ要件を満たす必要があります。 |
処理別に見ると
| 処理 | 費用を決める主因 | 安くする方向 |
|---|---|---|
| 画像入力・画像解析 | 画像サイズ、detail、モデル、画像枚数 | detail="low"、不要な余白を切る、画像枚数を減らす |
| 高精度な画像理解 | detail="high" / original、画像サイズ | 必要な時だけhigh/originalにする |
| 画像生成 | 出力サイズ、quality、出力枚数、モデル | quality="low"、小さめサイズ、1枚生成から始める |
| 画像編集 | 元画像サイズ、参照画像数、quality、出力サイズ | 編集元を必要範囲に絞る、参照画像を減らす |
| マスク編集 | 元画像とマスクのサイズ・形式、出力条件 | マスクと元画像のサイズを合わせる。不要に大きい画像を避ける |
ファイル形式の扱い
| 形式 | 入力対応 | 費用面の見方 |
|---|---|---|
| PNG | 対応 | 画質劣化が少ないがファイルサイズは大きめ。費用は主に寸法/detailで決まります。 |
| JPEG / JPG | 対応 | 写真向き。ファイルサイズを小さくしやすい。通信・保存には有利。 |
| WEBP | 対応 | 圧縮効率がよい。通信量削減に有利。 |
| 非アニメーションGIF | 対応 | 入力可。ただし通常はPNG/JPEG/WebPのほうが扱いやすいです。 |
| アニメーションGIF | 基本的に対象外 | 静止画像として扱う前提にしたほうが安全です。 |
実務上のおすすめ
| 目的 | 推奨設定 |
|---|---|
| ざっくり何が写っているか知りたい | detail="low" |
| 文字・細部・位置関係を読みたい | detail="high" または original |
| UI画面、クリック位置、細かいレイアウトを見たい | original 寄り |
| 画像生成のラフ案をたくさん試したい | quality="low"、小さめサイズ、1枚ずつ |
| 最終成果物を作りたい | quality="medium" または high |
| 費用を抑えたい | 小さいサイズ、低detail、低quality、少ない枚数 |
今回の測定でも、画像入力解析は約0.4円、画像生成1枚は約1円、画像編集は約2.3円と、編集は参照画像・入力画像を含むぶん生成より高くなりやすい傾向が出ていました。
参照: Images and vision, Image generation
付録:音声関連の処理で費用に影響を与える因子
音声関連は、処理方式ごとに課金軸が違います。まず大枠はこうです。
| 処理 | 主な課金軸 |
|---|---|
| Realtime音声会話 | 入力音声トークン、出力音声トークン、テキストトークン |
| Realtime文字起こし | 音声時間ベース、または文字起こし用usage |
| Realtime音声翻訳 | 音声時間ベース |
| ファイル文字起こし | 音声ファイルの長さ、モデル、追加機能 |
| Text to Speech | 入力テキスト量、生成される音声量、モデル |
| 音声つき会話履歴 | 会話履歴・キャッシュ・ターン数 |
費用に影響する因子
| 因子 | 影響する処理 | 費用への影響 | 説明 |
|---|---|---|---|
| 入力音声の長さ | 音声会話、文字起こし、翻訳 | 大 | 長いほど入力音声トークン、または課金対象秒数/分数が増えます。 |
| 出力音声の長さ | 音声会話、TTS、音声翻訳 | 大 | 長く話させるほど出力音声トークンや生成音声量が増えます。 |
| 会話ターン数 | Realtime音声会話 | 大 | Realtime会話では会話履歴が次ターンの入力に入るため、後半のターンほど高くなりやすいです。 |
| 無音区間 | Realtime音声会話、文字起こし | 中〜大 | VADが有効なら無音は除外されやすいですが、手動で無音音声を入力に追加すると課金対象になり得ます。 |
| モデル | 全音声処理 | 大 | gpt-realtime-2、gpt-realtime-whisper、gpt-realtime-translate、gpt-4o-transcribe、gpt-4o-mini-transcribe、gpt-4o-mini-tts などで単価が違います。 |
| 出力品質モデル | TTS | 大 | tts-1 は低遅延寄り、tts-1-hd は高品質寄りです。高品質モデルは一般に高くなりやすいです。 |
| 音声速度 | TTS、音声会話 | 中 | ゆっくり話す指示にすると出力秒数が伸び、費用が増える可能性があります。 |
| 声・voice | TTS、Realtime音声出力 | 小〜中 | voice自体で大きく費用が変わるというより、話し方・速度・出力時間に影響する場合があります。 |
| 入力ファイル形式 | ファイル文字起こし | 小 | mp3, mp4, mpeg, mpga, m4a, wav, webm が対応形式です。形式そのものより、音声長とモデルが費用に効きます。 |
| 出力ファイル形式 | TTS | 小 | mp3, opus, aac, flac, wav, pcm など。API費用より、ファイルサイズ・再生遅延・保存容量に効きます。 |
| サンプリングレート/ビットレート | 主に入出力ファイル | 小〜中 | 同じ発話時間なら課金への直接影響は限定的ですが、ファイルサイズ、25MB制限、転送時間に効きます。 |
| ステレオ/モノラル | 主に入力ファイル | 小〜中 | ステレオはファイルサイズが増えます。認識用途ならモノラルで十分なことが多いです。 |
| 文字起こしの詳細度 | ファイル文字起こし | 中 | verbose_json、単語タイムスタンプ、話者分離などは処理が重くなる・対応モデルが限られる場合があります。 |
| 話者分離 | 文字起こし | 中〜大 | gpt-4o-transcribe-diarize など専用モデル・追加設定が必要です。 |
| キャッシュ | Realtime音声会話 | 中 | 会話履歴がキャッシュされると入力コストを下げられる場合があります。ただし保証ではありません。 |
| 入力テキスト量 | TTS | 中 | 読み上げる文章が長いほど生成音声も長くなり、費用が増えます。 |
指示文 instructions | TTS | 小〜中 | 指示文自体の入力量に加え、話し方が長くなると出力音声も増えます。 |
形式ごとの見方
| 形式 | 主な用途 | 費用面の見方 |
|---|---|---|
| MP3 | 入力・TTS出力 | 圧縮率が高く汎用。費用より通信量削減に有利。 |
| WAV | 入力・TTS出力 | 非圧縮で大きいが、低遅延・処理しやすい。ファイルサイズ制限に注意。 |
| PCM | Realtime / 低遅延出力 | ヘッダなしの生音声。低遅延向きだが扱いはやや実装寄り。 |
| Opus | TTS出力 | ストリーミング・通信向き。低遅延用途に向く。 |
| AAC | TTS出力 | モバイル・動画系との相性がよい。 |
| FLAC | TTS出力 | 可逆圧縮。保存品質重視。 |
| M4A / MP4 / WebM | 入力文字起こし | ファイル文字起こしで対応。圧縮で25MB制限に収めやすい。 |
実務上の節約ポイント
| 目的 | 推奨 |
|---|---|
| 文字起こしを安くしたい | 無音を削る、必要部分だけ切り出す、圧縮形式で25MB以内にする |
| Realtime音声会話を安くしたい | VADを使う、短く答えさせる、会話履歴を長くしすぎない |
| TTSを安くしたい | 読み上げ文を短くする、話速を遅くしすぎない、必要な音声だけ生成する |
| 低遅延にしたい | RealtimeならWebRTC/PCM系、TTS出力なら wav / pcm を検討 |
| ファイルサイズを抑えたい | MP3 / Opus / AAC / WebM を使う |
| 高品質保存したい | WAV / FLAC を使う。ただしファイルサイズは大きい |
今回の測定結果との対応
今回のサンプルでは、
| 処理 | 内容 | 概算 |
|---|---|---|
| Realtime音声会話 | 約5秒入力+短い音声回答 | 約0.56円 |
| 音声文字起こし | 約10秒音声 | 約0.46円 |
| 音声翻訳 | 約10秒音声を英訳・音声生成 | 約0.92円 |
短い音声ではかなり低額でしたが、音声処理は基本的に 秒数・分数に素直に比例しやすいです。
1分、10分、1時間と伸びると、そのまま差が大きくなります。
参照: Realtime costs, Speech to text, Text to speech, Realtime and audio