
Mac版のCodexアプリが出たということなので覗いてみた。コーディング用途ではないので、Codexの概要、ローカルファイル処理方法、自動化方法を重点的に調べた。
(注)本記事の内容は正確性を保証するものではない。
(2026年2月9日 追記)YouTube動画を追加しました。 https://youtu.be/RceRDIvQHHQ
(2026年2月9日 追記)本記事で説明したSkills(スキル)は、「Codex専用の閉じた仕組み」ではなく、Anthropicが提唱した Agent Skills標準 に基づくオープン仕様なので、対応している他社のAIエージェントでもそのまま(か、ほぼそのまま)使える業界標準?だということが分かったので、この内容について、本記事の最後に、「Agent Skills」という内容を追記した。
Codexアプリ(Mac版) 画面構成
まず、画面構成を紹介する。
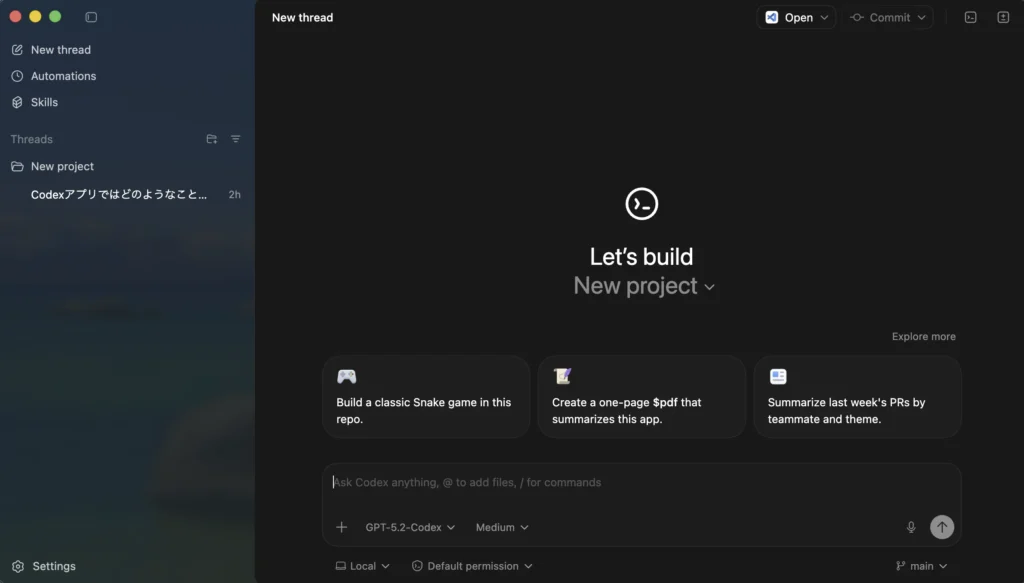
GPT-5.2-Codexアプリ(Mac版)の機能
GPT-5.2-Codexアプリ(Mac版)はどのようなことができるかを調べてください
Perplexityの回答
GPT-5.2-Codexアプリ(Mac版)は、「AIコーディング用の司令塔」みたいな立ち位置で、GPT-5.2-Codexモデルを中心に複数のエージェントを並行稼働させながら開発作業を自動化・支援できるデスクトップアプリです。openai+3
ざっくりできること
- GPT-5.2-Codexなどのコード特化モデルで、数百行〜複数ファイルにまたがる修正や生成をまとめて行う。gizmodo+1
- 複数のAIエージェントを同時に走らせ、調査・実装・テストなどのタスクを並列で進めるプロジェクト指向のワークスペースを提供する。itmedia.co+2
- MacネイティブなデスクトップUIで、CLI版やブラウザ版Codexと同じアカウント・設定を共有しつつ使える。openai+2
コーディング支援・自動化
- コード生成・リファクタリング・バグ修正・テストコード生成などを、会話形式で依頼できる。
GPT-5.2-Codexは「長く粘り強く思考」するようチューニングされており、大規模リファクタリングやフレームワーク移行のようなタスクもこなせる。issoh+1 - プロジェクト全体を読み込んだうえで、ファイルをまたぐ一貫した変更(API仕様変更の反映など)をまとめて提案してくれる。gizmodo+1
- 内蔵のGitツールと連携し、差分の確認・コミット前レビュー・ブランチごとの作業などをアプリ内で完結できる。developers.openai+1
複数エージェントとマルチタスク
- プロジェクト(や「作業フォルダ」)ごとにスレッドを持てるUIになっており、「機能Aの実装」「機能Bのテスト」「ドキュメント整備」を別々のエージェントに並行して任せるといった運用ができる。itmedia.co+2
- Worktree(ワークツリー)機能により、複数のAIエージェントが別々の作業ツリー上でコードを編集でき、同じファイルを同時に触ってコンフリクトだらけになる問題を避けられる。[youtube][developers.openai]
- 長時間動かしっぱなしのタスク(大規模解析やコードベース全体の改善提案など)も、他の作業と並行して進められるように設計されている。gihyo+2
Skills(スキル)と外部ツール連携
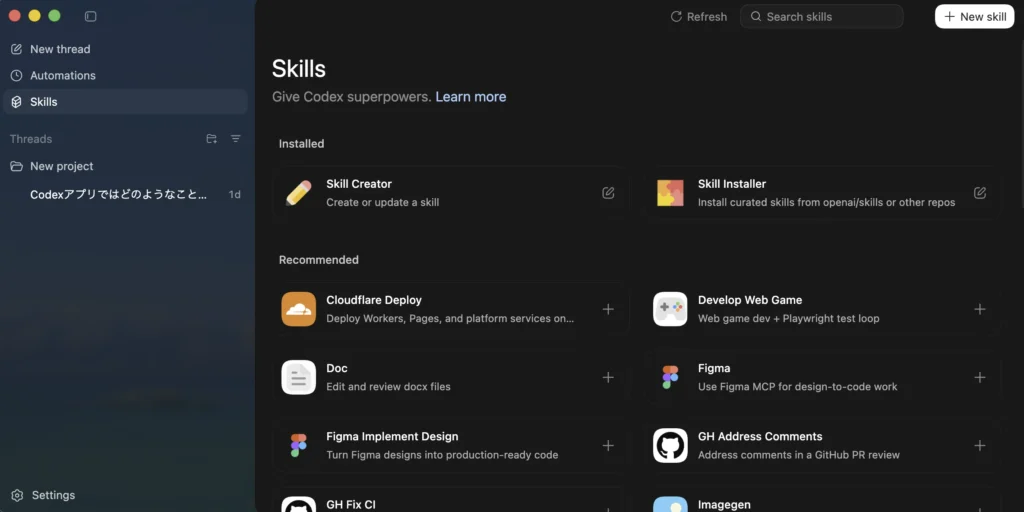
- 「Skills」という拡張機構で、GitHubリポジトリなどの外部ツール・API・自作スクリプトをエージェントから呼び出せるようにできる。developers.openai+2
- ユーザー自身のスキルを
~/.agents/skillsから読み込ませることで、プロジェクト固有のビルドツールやデプロイスクリプトをAI経由で実行する、といった拡張が可能。[developers.openai] - ChatGPT Atlas(AIブラウザ)と連携して、Codexアプリ内からWeb調査させる、リポジトリの外のドキュメントを参照させる、といった使い方もできる。openai+1
ドキュメント・ファイル・メディア系
- PDFや各種ドキュメントをアップロードし、仕様書の要約、設計書からの要件抽出、README自動生成といったタスクを行わせることができる。gizmodo+1
- 音声書き起こし機能で、会議やレビューの音声から議事録やチケット起こしを自動化できる。[gizmodo]
- 動画生成AI「Sora」との連携により、プロダクト紹介動画やチュートリアル動画の生成もアプリからトリガーできる。[gizmodo]
開発環境としての特徴(Mac版)
- macOS向けのネイティブアプリで、ChatGPTのPlus/Pro/Business/Enterprise/Eduなど有料プラン契約者が追加料金なしで利用開始できる(利用量に応じた追加クレジット購入も可)。openai+2
- CLI(
codexコマンド)、Web版(chatgpt.com/codex)、IDE拡張(VS Codeなど)とアカウントと設定が共有されるため、ターミナルやエディタで着手した作業をデスクトップアプリ側で引き継いで監視・制御できる。zenn+2 - macOSの音声入力(ボイスディクテーション)を利用した音声プロンプトにも対応し、手をキーボードから離さずに指示を出せるようになっている。developers.openai+1
もしよければ、「Xcodeのプロジェクトをどう使わせたいか」「Webアプリか、インフラ系スクリプトか」など、想定ユースケースを教えていただければ、そのシナリオに寄せた具体的な使い方フローも整理します。
コーディングに関する処理しかできないのでしょうか。
ローカルにあるPDFファイルやEXCELファイルに対する処理を自動化するような用途にも使えますか
Perplexityの回答
結論からいうと、Codexアプリ(GPT-5.2-Codex)は「コーディング専用」ではなく、ローカルのPDFやExcelを含むドキュメント処理・自動化にも使えます。openai+1
コーディング以外にできること
- Codexは「コードを書くAI」から、「コードを使ってPC上の作業をこなすAI」に進化したとされ、情報収集・要約・ライティングなど一般タスクもスキル経由で扱えます。[openai]
- オートメーション機能により、スケジュールに応じてバックグラウンドでタスクを実行し、結果をレビューキューに送るような「定期バッチ処理」のような使い方が想定されています。[ai-market]
PDF・Excelなどローカルファイルへの対応
- OpenAI公式の説明で、Codex用のスキル群として「PDF・スプレッドシート・docxファイルを読み取り・作成・編集する」ドキュメント生成スキルが用意されていることが明記されています。[openai]
- これらのスキルを使うと、PDFやExcel(スプレッドシート)を読み込んで要約する、データを抽出して別形式に変換する、集計済みのレポートを自動生成する、といった処理をコードなしで指示できます。note+1
- 最近のアップデートで「任意のファイルタイプを添付・ドロップできる」ようになっており、ローカルファイルを直接スレッドに渡したうえで処理させるワークフローが公式にサポートされています。[developers.openai]
どこまで自動化できるか(イメージ)
- 定期的にフォルダ内のExcelを読み込み、シートを結合して集計し、PDFレポートを生成して保存する、という一連の処理をオートメーション+スキルとして組むことができます。ai-market+1
- 会議資料PDFを投入して、要約+アクションアイテム抽出+タスク管理用CSVを作る、といった「ドキュメント→構造化データ」変換もスキルとスクリプトの組み合わせで実装可能です。ai-market+1
大雑把にいうと、「Gitリポジトリに対するエンジニアリング自動化」が主用途ですが、スキルとオートメーションを使えば、ローカルのPDF/Excelを対象にした事務・レポート系の自動処理にも十分使える設計になっています。openai+1
Codex Automationsの場合、整形/保存/追記などの後処理を追加できるのですか
Perplexityの回答
できます。Automationsは「指示+スキル」を自由に組み合わせられるので、整形・保存・追記などの後処理も含めて一連の流れとして書けます。developers.openai+1
Automationsで後処理を入れる考え方
- Automation本体は「自然文のinstructions」のみですが、その中で
$skill-nameを呼び出す- どのファイルにどう書き込むかまで具体的に指示する
ことで、前処理→分析→整形→保存→追記までまとめて実行させられます。[developers.openai]
- 後処理のロジックは Skill側(
SKILL.md+スクリプト) に書いておくと、Automationから何度でも再利用できます。blog.heftiweb+2
具体的なイメージ例
1. 整形して別ファイルに保存
Automation instructions 例:
毎朝9時に
$pdf-tables-to-csvスキルを使って昨日のPDFからテーブルを抽出し、
その後$csv-to-excel-reportスキルで
- 列名を日本語にリネーム
- 不要な列を削除
reports/daily_report.xlsxとして保存
まで行ってください。
ここで「列名リネーム」「不要列削除」「XLSX保存」が後処理で、csv-to-excel-report スキルのワークフローとして記述します。macaron+1
2. 既存ファイルへの追記
Skillのワークフロー例(要約):
summary_log.mdがあれば内容を読み込む。- 最新実行分の要約をMarkdownの1セクションとして末尾に追記。
- ファイルを上書き保存する。
Automation instructions 例:
$analyze-logsスキルで本日のエラーログを要約し、その結果を$append-to-summary-logスキルでlogs/summary_log.mdに追記してください。
このように「追記専用スキル」を用意すれば、Automationは毎回「分析→追記」を自動で回せます。macaron+1
3. フォーマット変換+保存場所の切り替え
- Markdown → HTML →
public/に書き出し - JSON → 整形して
archive/に日付付きファイル名で保存
といった処理も、Skill側に
- 変換処理(Pythonスクリプトなど)
- 出力パス・命名規則(例:
archive/report-YYYYMMDD.json)
を書いておけば、Automationから一行で呼び出せます。developers.openai+1
まとめると、Codex Automationsは「やりたい一連の処理を自然文+$スキル名で書く」スタイルなので、整形・保存・追記といった後処理はスキルとして定義しておけばいくらでも追加可能です。レビューは従来どおり、Triage/Reviewキューで人間が確認してから反映、という運用が推奨されています。developers.openai+1
PDFファイル処理
ここでは、PDFファイルに関連する処理について調査結果を紹介する。
スキル機能でPDFファイルを読み込む具体的な使い方を教えてください
Perplexityの回答
Codexの「スキル」を使うと、PDF処理用のワークフローを一度定義しておけば、毎回細かいプロンプトを書かなくても「このPDFを要約して」「このフォルダのPDFを集計して」と指示するだけで動かせます。openai+2
ここでは「既存のPDFスキルを使う場合」と「自作スキルを作る場合」で分けて、Mac版アプリ前提で流れを整理します。
1. 既存のPDFスキルを使う基本的な流れ
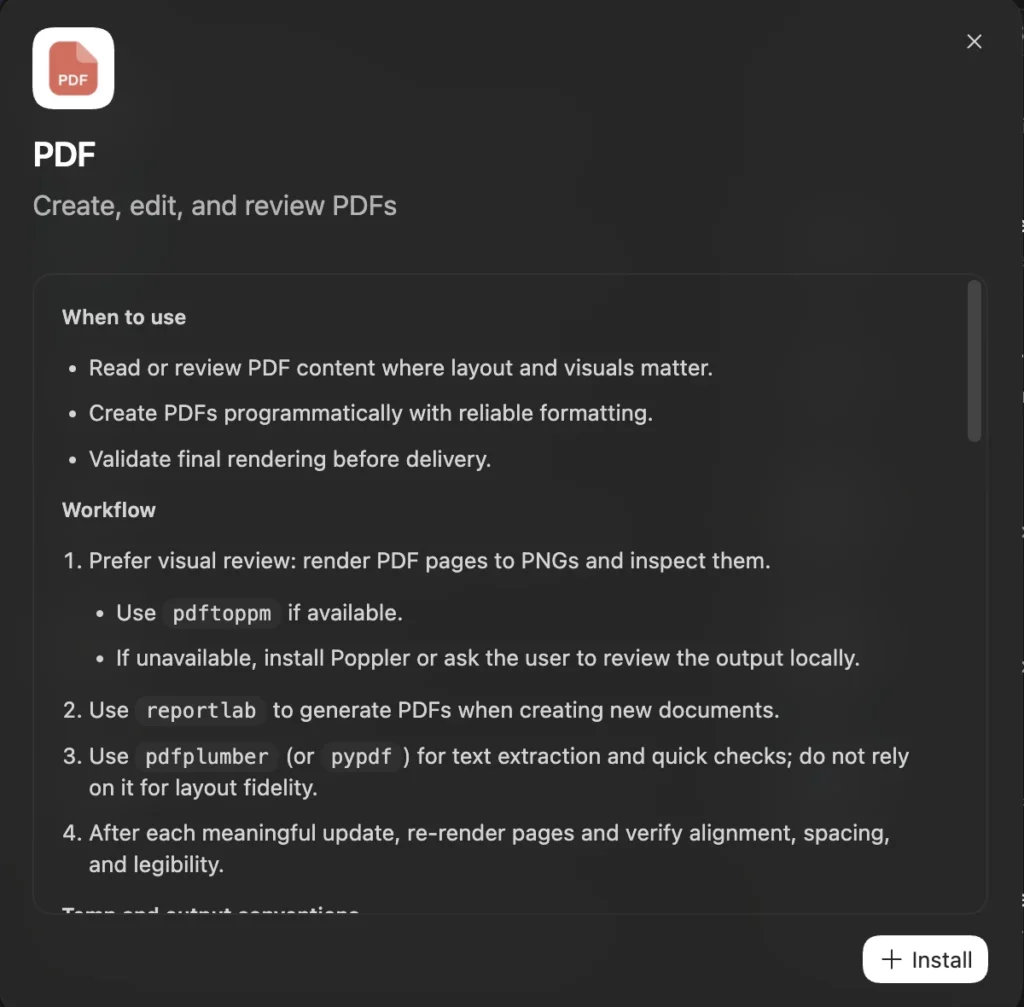
多くの環境では、OpenAIやコミュニティが用意した「PDFドキュメント用スキル」が最初からバンドルされているか、数クリックで追加できます。note+1
- Codexアプリでプロジェクト(ワークスペース)を開く
- 例:PDFをまとめて処理したいフォルダを「プロジェクト」として選ぶ。[blog.heftiweb]
- 右側か上部メニューから「Skills」パネル(または設定画面)を開く
- 「Create documents」「PDF」「Document skills」といった名前のスキルセットが表示されます。openai+1
- PDF関連スキルを有効化する
- 「PDFを読み取り・作成・編集するスキルセット」と説明された項目をオンにするか、インストールします。note+1
- チャットでPDFをドラッグ&ドロップしながら指示する
- スレッドにPDFファイルをドロップして、例えば次のように頼みます:
- 「このPDFの要約を作成して」「このPDFから表だけを抽出してCSV化して」など。platform.openai+1
- Codex側は、バックエンドで「PDFスキル」を選んでテキスト抽出・レイアウト解析などを行い、結果を回答として返します。reddit+2
- スレッドにPDFファイルをドロップして、例えば次のように頼みます:
- スキル名を明示して呼び出す(サポートされている場合)
- UIや説明に従って「
$pdfスキルを使ってこのファイルを解析して」など、専用の呼び出しシンタックス($pdfやスラッシュコマンド)を使うケースもあります。developers.openai+1
- UIや説明に従って「
2. 自作PDFスキルを作るイメージ
もっと細かい「自分専用のPDF処理フロー」(例:決まったテンプレで要約、特定ページだけ抽出など)を組みたい場合は、~/.codex/skills 以下に自作スキルを置きます。zenn+1
スキル用ディレクトリを作成
ターミナルでmkdir -p ~/.codex/skills/pdf-report のようにフォルダを作成。[blog.heftiweb]
SKILL.md を作成
・そのフォルダ内に SKILL.md を作ります。
・冒頭にYAML風ヘッダを書きます(例):
name: pdf-report
description: プロジェクトのPDFを読み込み、要約とアクションアイテムをMarkdownレポートとして生成するスキル
allowed-tools: [python, shell, openai-api]本文にワークフローを書く
同じ SKILL.md の本文に、「どういう手順でPDFを処理するか」を人間向け手順として書いておきます
(Codexはこれを読み取り、実行用スクリプトを組み立てます)。zenn+1
例(かなり簡略化):
# Workflow
1. 指定されたフォルダから .pdf ファイルを列挙する。
2. 各PDFについてテキストを抽出する(PyPDF2やpdfminerなどを使用)。
3. 抽出テキストをGPT-5.2-Codexに渡し、要約とTODOリストを生成する。
4. 結果を1つのMarkdownファイル (summary.md) に追記していく。
5. 完了したら、summary.md のパスをユーザーに通知する。Codexはこの内容を見て、必要ならPythonスクリプトやシェルコマンドを提案・実行してくれます。robert-glaser+1
Codexを再起動 or プロジェクト再読み込み
アプリを再起動するか、スキル再スキャンを行うと、新しい pdf-report スキルが一覧に出てきます。heftiweb+1
チャットからスキルを使う
プロジェクト内で、次のように指示します:
「このプロジェクトのPDFに対して pdf-report スキルを実行して」
Codexは## Skillsセクションにある説明を見て、SKILL.mdを読み込み、そこに書かれた手順に沿うPythonスクリプトなどを自動生成・実行します。robert-glaser+1
3. 「ローカルPDFを読ませる」最小構成の実例イメージ
厳密なコードではなく、「どういう感じになるか」のイメージです。
- あなたがやること
- PDFファイルをプロジェクトフォルダに置く
- 既存のPDFスキルを有効化する or
SKILL.mdを書いて保存する - チャットで「このPDFを要約して」「フォルダ内すべてのPDFを対象に、スキルXを使って」と指示する
- Codexがやること(内部イメージ)
- スキル一覧からPDFスキルを見つける
- スキル説明や本文を読んで、必要ならPythonスクリプト(例:PyPDF2でテキスト抽出)を生成
- スクリプトを実行し、抽出したテキストをGPT-5.2-Codexに渡して要約・分析
- 結果をチャットに返すか、指定ファイル(summary.md, output.xlsxなど)に保存するstackoverflow+2
4. まず試しやすい入門パターン
- すでにバンドルされている「Create documents / PDF スキル」をオンにして、
- 「この添付PDFの要約を作って」
- 「このPDFから表を抽出してCSVにして」
といったシンプルな指示から試すのが一番楽です。openai+1
もしよければ、
- 「毎朝このフォルダのPDFを読んで日報を作る」
- 「ExcelとPDFを組み合わせたレポートを自動生成する」
など、やりたい自動化の具体像を教えてもらえれば、それを満たすSKILL.mdのひな形レベルまで落とし込んで提案できます。
PDFからテーブルを抽出する詳細な手順を教えてください
Perplexityの回答
CodexでPDFからテーブルを抽出する流れは、「PDF処理スキルを用意 → PDFを渡す → 抽出形式(CSV/Excel/Markdownなど)を指示」という3段階で考えると整理しやすいです。mynixos+2
1. 前提準備(PDFスキルの用意)
- CodexアプリでPDF用スキルを有効化
- Skills一覧に「PDF」「pdf-processing」「pdf skill」のようなスキルがあればオンにします。awesomeskill+1
- なければ、公開スキル(
pdfスキル)をインストールし、~/.codex/skillsなどのスキルディレクトリに追加してアプリを再起動します。github+1
- スキルが何をしてくれるかを確認
- 多くのPDFスキルは
pdfplumberやpypdfなどのライブラリを使い、「テキスト・テーブル・メタデータの抽出」をまとめて扱えるようになっています。mynixos+1
- 多くのPDFスキルは
2. 一番シンプルな使い方(ノーコード)
- CodexのチャットにPDFをドラッグ&ドロップ
- 抽出したい表を含むPDFを、そのまま会話スレッドに添付します。[datastudios]
- プロンプトでテーブル抽出を指示
- 例: このPDFから、すべてのテーブルを抽出して、ページごとに別々のCSVとして出力してください。
それぞれのCSVのプレビューと、ページ番号も教えてください。 - あるいは: このPDFの3〜5ページにあるテーブルだけを抽出して、1つのExcelシートに統合してください。行・列の構造がわかるようにしてください。
- 例: このPDFから、すべてのテーブルを抽出して、ページごとに別々のCSVとして出力してください。
- Codexが内部でやること(イメージ)
- PDFスキルを呼び出し、
pdfplumberなどでテーブル候補を検出。awesomeskill+1 - 各テーブルをDataFrame相当の構造にし、指定された形式(CSV/Excel/Markdownなど)に変換。
- 場合によってはZIPや1つのまとめファイルとして返してくれます(ChatGPT系のワークフローと同様)。[datastudios]
- PDFスキルを呼び出し、
3. ページやテーブルを細かく指定したい場合のプロンプト例
- ページ指定あり: 添付したPDFについて、ページ2〜4に含まれるテーブルのみを抽出してください。
1つのCSVにまとめ、1列目に「page」列として元のページ番号を入れてください。 - テーブル位置を絞る: このPDFの1ページ目中央にある「売上サマリ」テーブルだけを抽出して、Markdown形式の表として表示し、その後CSVもダウンロードできるようにしてください。
Codex側はPDFレイアウトを解析し、対象テーブルだけを抽出するようスクリプトを組み立てます。stackoverflow+2
4. 自作スキルで「PDF→CSV変換」をルーチン化する
毎回同じ処理(例えば「PDFの全テーブル→CSV」)をしたいなら、専用スキルを1つ作っておくと楽です。github+2
4-1. スキル定義の例(~/.codex/skills/pdf-tables/SKILL.md)
---
name: pdf-tables-to-csv
description: プロジェクト内のPDFからテーブルを検出し、ページごとのCSVとして書き出すスキル
---
# Workflow
1. プロジェクト内のPDFファイル(またはユーザーが指定したPDFファイル)を特定する。
2. pdfplumber または camelot を使って、各ページのテーブルを検出・抽出する。
3. 各テーブルを pandas DataFrame に変換し、`tables/page-<page>-table-<index>.csv` というパスで保存する。
4. どのページから何個のテーブルを抽出したかを一覧にして、チャットに要約として表示する。
5. 必要であれば、すべてのCSVを1つのZIPファイルにまとめて出力する。このように書いておくと、Codexは pdfplumber や camelot を使ったPythonスクリプトを自動生成して実行するよう誘導できます。github+3
4-2. 実行時の指示
- プロジェクトでPDFを置いてから:
pdf-tables-to-csvスキルを使って、このプロジェクト内のすべてのPDFからテーブルを抽出し、CSVとして保存してください。完了したら保存先とファイル一覧を教えてください。
5. 表が崩れやすいPDFへの対処のポイント
- 罫線が薄い・ずれているPDFでは、テーブル検出精度が落ちるので、
- 「このページの図は無視して、明らかに表形式の箇所だけを抽出して」
- 「列境界が曖昧な場合は、空白文字数やアラインメントから列を推定して」
など、補足条件をプロンプトに含めると改善しやすいです。reddit+2
- スキャンPDF(画像ベース)の場合は、OCR前提の抽出になるため、 このPDFはスキャン画像です。OCRを使って表を読み取り、可能な範囲でテーブルとして再構成してください。誤認識しやすい数字(0/O, 1/I など)をチェックしてください。
と明記しておくと、スクリプト側でOCR+テーブル再構成の流れを組んでくれます。tableextract+1
必要であれば、「1つのPDFから特定のテーブルだけ取り出してExcelに貼りたい」といった具体的なPDF構造(ページ数・表の位置)を教えてもらえれば、そのケース専用のプロンプト文と SKILL.md の雛形まで作成します。
PDFフォーム入力のスキル活用例を教えてください
Perplexityの回答
PDFフォーム(AcroFormやfillable PDF)も、スキルを組むと「ExcelやCSVから一括入力」「対話で埋める」などかなり自動化できます。awesomeskill+1
以下、Codexスキルでの活用パターン例です。
1. ExcelリストからPDF申請書を一括生成
用途:社員一覧や顧客一覧のExcelから、同じ様式の申請書・契約書PDFをまとめて作る。
イメージワークフロー(スキル内容)
applicants.xlsxを読み込み、行ごとに「氏名・住所・生年月日…」を取得。- テンプレートPDFフォーム
template.pdfの各フィールド名とExcel列をマッピング。 - 各行についてPDFコピーを作り、対応フィールドに値をセット。
- /output/<氏名>.pdf のような名前で保存する。
プロンプト例
スキル
pdf-form-fill-from-excelを使って、
template.pdfをフォームテンプレートapplicants.xlsxの各行を入力データ
として、行ごとに1ファイルずつPDF申請書を作成してください。完了したら生成されたPDF一覧を教えてください。
2. チャットで質問されながらフォームを埋める
用途:人事・総務の担当者が質問に答えるだけでPDFを完成させたい場合。
イメージワークフロー
- スキルが
template.pdfのフォームフィールド名を読み取る(例:name,address,phone,date)。[github] - 足りない値は、チャット経由で順番に質問する。
- すべて埋まったら、PDFを保存+プレビュー用に要約を表示。
プロンプト例
template.pdfのフォームを埋めたいので、スキルinteractive-pdf-form-fillを使って、必要な項目を1つずつ日本語で質問しながら入力してください。
入力が終わったら、作成したPDFをfilled_form.pdfとして保存し、内容の要約も表示してください。
3. 既存PDFフォームからデータをCSV化(逆方向)
用途:提出済みPDFフォームを大量に集計したいとき。
イメージワークフロー
- 指定フォルダ内のPDFフォームを走査。
- 各フォームのフィールド値(氏名・部署・金額など)を読み取る。awesomeskill+1
- すべてを1つのCSVにまとめる(1行=1ファイル)。
プロンプト例
スキル
pdf-forms-to-csvを使って、このフォルダ内のすべてのPDFフォームから、
- 名前
- 部署
- 申請金額
を抜き出し、forms_summary.csvにまとめてください。
4. 入力チェック+差し戻しコメントを自動化
用途:入力漏れ・不正値があるフォームを検知して指摘。
イメージワークフロー
- PDFフォームから値を読み出す。
- 必須項目ブランク、日付フォーマット不正、金額の範囲チェックなどのルールを適用。
- 問題のあるフィールド名と理由を一覧にしてレポートを生成。
プロンプト例
/applications フォルダ内のPDFフォームすべてに対して、スキル
pdf-form-validateを実行し、
- 必須項目の空欄
- 日付フォーマット誤り(yyyy-mm-dd 以外)
- 金額が0以下
をチェックしてください。
問題があるファイルはファイル名ごとに、どの項目がNGかをMarkdownの表で一覧化してください。
5. 署名欄だけ空けてその他を自動入力
用途:署名だけ手書きする前提で、それ以外を自動で埋めたいとき。
イメージワークフロー
- テンプレPDFのフィールドのうち、
signature/sign_dateなど署名系だけ除外。 - それ以外のフィールドをExcelやチャット回答から自動入力。
プロンプト例
contract_template.pdfについて、スキルpdf-form-fill-partialを使い、
- 署名と署名日 (signature, sign_date フィールド) 以外のすべての項目を自動入力してください。
入力値はclient_info.xlsxの「契約先」シートから取得し、完成したPDFをcontract_draft.pdfとして保存してください。
こういう形で、「どこからデータを取るか」「どこまで自動で埋めるか」「出力をどうまとめるか」をスキルに固定しておくと、PDFフォーム周りはかなり省力化できます。
ローカルPDFをアップロードして分析する方法
Perplexityの回答
ローカルのPDFは、Codexアプリに「ドラッグ&ドロップしてそのまま分析させる」か、「スキル経由でワークフローに組み込む」のが基本です。developers.openai+1
ここでは、Mac版Codexアプリ前提での具体的な手順をまとめます。
1. もっとも簡単な方法(ドラッグ&ドロップ)
- Codexアプリで任意のスレッド(チャット)を開く。
- FinderからPDFファイルをつかんで、Codexの入力欄(プロンプトエリア)にドラッグ&ドロップする。
- 添付用のUIがある場合は、「ファイルを添付」ボタンから選んでもOKです。[developers.openai]
- 分析内容を自然言語で指示する。例:
- 「このPDFの内容を3点に要約して」
- 「このレポートの重要な数字と結論を箇条書きにして」
- 「このPDFの中で、セキュリティに関する指針が書かれている部分を抜き出して要約して」
Codexは内部でPDF用のスキルセット(ファイル読み取り能力)を使い、テキスト抽出+要約・分析を行います。openai+1
2. プロジェクトにPDFを置いて、継続的に分析する
- Codexアプリで「プロジェクトとして開く(Open project)」から、PDFが置かれているフォルダを選択。
- プロジェクトに紐づいたスレッドで、PDFファイル名を指定して指示します。
- 例: このプロジェクト内の
report_2025.pdfを読み込んで、章ごとの要約と、気になるリスク事項のリストを作ってください。
- 例: このプロジェクト内の
- 必要に応じて、
- 「同じフォルダにあるすべてのPDFを対象にして」
- 「最新の日付のPDFだけを対象にして」
など、フォルダ単位の指定も可能です。[linkedin]
3. スキルを使って「分析パターン」を固定する
毎回同じ分析(例:章別要約+アクションアイテム抽出)をしたい場合は、PDF解析用のスキルを1つ作っておくと便利です。github+1
3-1. スキルのイメージ(pdf-analyze-report)
~/.codex/skills/pdf-analyze-report/SKILL.md のような形で、以下のようなワークフローを書きます:
---
name: pdf-analyze-report
description: PDFレポートを読み込み、章ごとの要約とリスク・アクションアイテムを抽出するスキル
---
# Workflow
1. ユーザーが指定したPDFファイルを開く。
2. 各セクション(章・節)ごとにテキストを抽出する。
3. 抽出したテキストを GPT-5.2-Codex に渡し、章ごとの要約を生成する。
4. 全体を通して、リスク事項・TODO・決定事項を箇条書きで抽出する。
5. 章ごとの要約+リスク一覧を Markdown ファイルに保存し、チャットにも要約を表示する。Codexはこの記述をもとにPDF読み取り+要約コード(Pythonなど)を自動で組み立てます。awesomeskill+2
3-2. 実行時の指示
- プロジェクトでPDFを用意した上で: スキル
pdf-analyze-reportを使って、security_policy_2025.pdfを分析してください。
章ごとの要約と、リスク・改善提案を日本語で出してください。
4. ローカルPDFを使った「質問応答」的な分析
PDFを「知識ベース」として使い、質問に答えさせることもできます。platform.openai+1
- PDFをプロジェクトに置く or スレッドに添付。
- プロンプトで: このPDFの内容だけを根拠に、以下の質問に順番に答えてください。
- この文書の目的は何か
- 導入されている主なルールは何か
- 利用者にとって注意すべき点は何か
- 必要なら、RAG(ベクタ検索)用のスキルを追加し、
- PDFからチャンクを作成して埋め込み
- 質問時に近いチャンクを検索してから回答
という形にもできます。[linkedin]
5. 実務でよく使うプロンプト例(コピペ用)
- 「PDFの全体要約」 添付したPDFの内容を、非専門家向けに3〜5点で要約してください。重要な数字や結論があれば必ず含めてください。
- 「アクションアイテム抽出」 このPDFから、「今後やるべきこと」「担当者付きで書かれているタスク」「期限付きの項目」をすべて抜き出して、Markdownのチェックリスト形式で出してください。
- 「比較観点の抽出」 このPDFに書かれているプランAとプランBについて、コスト・リスク・メリットの3軸で比較表を作ってください。文章中の記述を整理して構いません。
このあたりをベースに、「どのフォルダのPDFを」「どんなフォーマットのアウトプットにするか(Markdown / CSV / Excel / JSON)」まで決めると、かなり強力なPDF分析環境になります。
複数ページのPDFから全テーブルを抽出する方法を教えてください
Perplexityの回答
複数ページPDFから「全テーブル」を抜くときは、
(1) PDF添付 → (2) テーブル抽出を明示 → (3) 出力形式を指定、の3ステップで指示すると安定します。github+1
1. 一番シンプルな指示例(ノーコード)
PDFをチャットにドラッグ&ドロップして、次のように指示します。
このPDFは複数ページあります。すべてのページからテーブルを検出・抽出し、
- 各テーブルを page-<ページ番号>-table-<連番>.csv として出力
- どのページから何個テーブルが見つかったかを一覧表示
を行ってください。
Codex側では内部でPDF用スキル(pdf / pdf-processing など)を呼び、pdfplumber や camelot のようなライブラリで全ページを走査してテーブル抽出を行うイメージです。stackoverflow+2
2. 「全ページ+1つのCSVに結合」のプロンプト例
ページごとのテーブルを1つの大きなテーブルにまとめたい場合:
添付したPDFについて、すべてのページからテーブルを抽出し、
- 列構造が同じテーブルは1つの大きなテーブルに縦結合
- 先頭列に page 列を追加して元のページ番号を保持
というルールでall_tables.csvにまとめてください。
これで、Tabula系ライブラリがページごとに分けてしまっても、後段で縦結合する処理を自動で組んでくれます。stackoverflow+1
3. スキルでルーチン化する場合の SKILL.md 例
複数ページPDFから全テーブルをCSV化する専用スキルのイメージです。
---
name: pdf-multi-page-tables
description: 複数ページのPDFから全テーブルを抽出し、CSVとして保存するスキル
---
# Workflow
1. ユーザーが指定したPDFファイルを開く。
2. すべてのページを走査し、pdfplumber などでテーブル候補を検出する。
3. 各テーブルを pandas DataFrame に変換し、
- `tables/page-<page>-table-<index>.csv` として個別保存、
- 必要に応じて列構造が同じものを縦結合して `tables/all_tables.csv` を作成する。
4. どのページから何個テーブルを抽出したかのサマリを作り、チャットに表示する。
こう書いて ~/.codex/skills/pdf-multi-page-tables/SKILL.md に置くと、
Codexが「全ページ走査→テーブル抽出→CSV出力」まで一気通貫でやるワークフローを組みやすくなります。skillsmp+2
実行時は:
スキル pdf-multi-page-tables を使って、このPDFから全ページのテーブルを抽出し、CSVにして保存してください。完了したらファイル一覧と簡単なサマリを教えてください。
のように呼び出すだけでOKです。
4. マルチページにまたがる長いテーブルへの一言
1つの表が2ページ以上にまたがる場合、ライブラリはページごとに分割して認識しがちなので、プロンプトに
同じ列構造のテーブルが連続ページに現れた場合は、1つのテーブルとして結合してください。
ヘッダ行が2ページ目以降にない場合は、1ページ目のヘッダを流用してください。
と書き足すと、後処理の結合ロジックをAIに組ませやすくなります。reddit+1
もし、「このPDFで実際にやりたい抽出(どんなテーブルか、CSVかExcelか)」が決まっていれば、その用途にどんぴしゃなプロンプト文まで日本語で整形します。
EXCELファイル処理
次にEXCELファイルに対する処理の例を紹介する。
Excelファイルをスキルで読み込む具体的な方法を教えてください
Perplexityの回答
Excel(スプレッドシート)も、PDFと同じく「スキル」で読み込み・加工できます。openai+1
大きく「既存のスプレッドシート系スキルをそのまま使う」と「自作スキルを作る」の2パターンがあります。
1. 既存のスプレッドシートスキルを使う基本手順
Codexアプリには「スプレッドシート(spreadsheet/xlsx)を読み取り・作成・編集するスキルセット」が含まれています。openai+2
- Codexアプリでプロジェクトを開く
- 対象のExcelファイル(.xlsxなど)が入ったフォルダをプロジェクトとして指定します。[blog.heftiweb]
- Skills(スキル)パネルを開く
- アプリ内の「Skills」や「Create documents」などのセクションで、
- 「スプレッドシート操作」「spreadsheet skill」「xlsx」といった説明のあるスキルセットをオンにします。note+2
- アプリ内の「Skills」や「Create documents」などのセクションで、
- Excelファイルをチャットに渡す
- スレッドにExcelファイルをドラッグ&ドロップするか、「ファイルを添付」ボタンで追加します。[openai]
- そのうえで、自然言語で指示します(例):
- 「このExcelの売上シートを集計して、月ごとの売上サマリを出して」
- 「このファイルの中で、A列とB列の相関を見てグラフ作成用のデータを準備して」
- 処理内容をもう一段具体化すると精度が上がる
- 例:
- 「シート名 ‘Sales’ を対象に、列A=日付、列B=金額として月別合計を出し、結果を新しいシート ‘MonthlySummary’ に書き込んで」
- スプレッドシートスキルは内部で行・列やセル範囲を扱えるため、こうした指示に従って読み取り・加工・新規シート作成まで自動で行います。qiita+1
- 例:
2. 自分専用のExcelスキルを作るイメージ
ルーチン作業(例:毎回同じ列を集計して別シートに出す)を固定したい場合は、自作スキルにしておくと便利です。dev+1
2-1. スキルフォルダと SKILL.md 作成
1. ターミナルでスキル用フォルダを作成 mkdir -p ~/.codex/skills/xlsx-monthly-reportheftiweb+1
2. ~/.codex/skills/xlsx-monthly-report/SKILL.md を作成し、ヘッダを書く
---
name: xlsx-monthly-report
description: 「売上.xlsx」を読み込み、月別売上サマリを新しいシートに出力するスキル
metadata:
short-description: Excel売上データの定型集計
---
# Workflow
1. プロジェクト内の「売上.xlsx」を探す。見つからなければユーザーにファイル名を確認する。
2. シート名「Sales」を開き、列Aを日付、列Bを売上金額として解釈する。
3. 日付を月単位でグループ化し、月別合計を計算する。
4. 結果を新しいシート「MonthlySummary」に表形式で書き込む(列A=年月、列B=合計金額)。
5. 処理が完了したら「MonthlySummary」シートを保存し、サマリをチャットにもテキストで返す。こうしておくと、Codexがこの手順を読んで、Python+openpyxl や pandas などを使ったスクリプトを自動生成・実行してくれます。
3.Codexアプリを再起動 or スキル再読み込み
アプリが ~/.codex/skills をスキャンし、xlsx-monthly-report がスキル一覧に出るようになります。dev+1
2-2. スキルを呼び出してExcelを処理
- プロジェクトで、「売上.xlsx」がある状態にしてから、チャットで指示します:
- 「このプロジェクトの売上データに対して
xlsx-monthly-reportスキルを実行して」
- 「このプロジェクトの売上データに対して
- Codexはスキル一覧から
xlsx-monthly-reportを見つけ、SKILL.mdの手順どおりにExcelを読み込み・集計します。heftiweb+1
3. どんな処理が向いているか
スプレッドシートスキル+Excelファイルで、例えば次のような処理が現実的です。note+2
- 日次/週次/月次の売上・アクセス・在庫などの定型集計
- 「複数Excelファイルを1つにマージ」「特定シートだけ抜き出して別ファイルにする」
- 欠損値・外れ値チェック、簡単な統計(平均・中央値・標準偏差など)のレポート生成
- Excelを中間形式(CSV・JSON)に変換して、別のスキルや外部ツールに渡す前処理
4. 最初に試すなら
- Skillsで「スプレッドシート(spreadsheet/xlsx)」系スキルを有効化。openai+1
- 小さめのExcelを1つチャットに添付し、
- 「このExcelの内容を要約して」
- 「列Aと列Bの合計・平均を出して表を作って」
くらいの指示から試すのが安全です。openai+1
もし「こういうExcel(列構成)のファイルを、毎回こう処理したい」という具体例があれば、列名やシート構成を書いてもらえれば、それ前提の SKILL.md ひな形を日本語コメント付きで組み立てます。
Excel自動化のサンプルプロンプト例を教えてください
Perplexityの回答
Excel自動化でそのまま(または少し編集して)使えるプロンプト例を用途別にいくつか挙げます。
(前提:CodexアプリでExcelスキルを有効化し、対象ファイルをプロジェクトやチャットに添付してある状態)
1. 月次集計レポートを作る
目的:売上やアクセスログなどを「月別サマリ」にまとめる定型処理。
このプロジェクト内の
売上.xlsxを使って、月別売上レポートを作成してください。
前提条件は次のとおりです。
- 対象シート名: Sales
- 列A: 日付(yyyy-mm-dd形式)
- 列B: 売上金額(数値)
やりたいこと:
- 日付を月単位でグループ化し、月ごとの売上合計と平均を計算する。
- 結果を新しいシート
MonthlySummaryに出力する(列A=年月、列B=合計、列C=平均)。- 集計結果のサマリーコメント(どの月がピークか、傾向など)を日本語で短く書く。
2. 複数ファイルを縦に結合する
目的:同じ形式のExcelファイルを1つにまとめる。
このプロジェクトフォルダ内にあるすべての
.xlsxファイルのうち、シート名 Data を対象にしてください。
各ファイルのDataシートには、1行目にヘッダ行があり、2行目以降がデータです。やりたいこと:
- すべてのファイルの
Dataシートを読み込み、ヘッダ行は最初のファイルのみ採用する。- それらを縦方向に結合し、1つのシート AllData にまとめる。
- 結果を新規ファイル
merged_data.xlsxとして保存する。
3. 条件に合う行だけを抽出して別シートへ
目的:フィルタ条件でレポートを作る。
顧客一覧.xlsxのシートCustomersを使って、条件に合う顧客だけを抽出してください。
- 列A: 顧客ID
- 列B: 顧客名
- 列C: ステータス(例: Active, Inactive)
- 列D: 最終購入日(yyyy-mm-dd)
やりたいこと:
- ステータスが Active かつ、最終購入日が「今日からさかのぼって180日以内」の行だけを抽出する。
- 抽出結果を新しいシート
ActiveRecentに出力する。- 該当件数と、代表的な顧客5件の一覧をチャットにも表示する。
4. 欠損値チェックと簡易データクレンジング
目的:分析前の前処理を自動化。
調査結果.xlsxのシートRawに対して、欠損値と異常値のチェックを行ってください。
前提:
- 列A: レコードID
- 列B: 年齢
- 列C: 年収
タスク:
- 年齢が 0 未満または 120 超の行を「年齢異常」としてフラグを立てる。
- 年収が 0 以下または 1億以上の行を「年収異常」としてフラグを立てる。
- いずれかの列が空欄の行を「欠損」としてフラグを立てる。
- これらのフラグを付けた結果を新シート Checked に書き出し、異常・欠損の件数サマリをチャットに表示する。
5. 日本語でレポート文まで自動生成
目的:Excel集計+文章レポート作成まで一気に。
アクセスログ.xlsxのシートDailyをもとに、週次アクセスレポートを作成してください。
- 列A: 日付
- 列B: PV(ページビュー)
やりたいこと:
- 日付を週単位にグループ化し、週ごとのPV合計を計算する。
Weeklyシートに、週開始日・週終了日・PV合計の表を作成する。- その結果をもとに、「今週のPVは先週比で何%増減か」「全期間でどの週が最大か」などを含む日本語レポート文を、Markdown形式で1〜2段落生成する。
6. 「スキル前提」の定型プロンプトひな形
スキル化してある前提で、「毎回これだけ打てばいい」形の例です。
スキル
xlsx-monthly-reportを使って、このプロジェクト内の最新の売上ファイルに対して月次レポートを実行してください。
- 「売上_YYYYMM.xlsx」というファイル名パターンから、もっとも新しい年月のファイルを対象にする。
- レポートが完了したら、生成されたシート名と、主要なサマリ指標(合計売上、平均、最大月)だけをチャットに要約して報告してください。
もし「実際はこういう列構成のファイルを毎日処理したい」といった具体例があれば、列名入りで教えていただければ、それ専用のプロンプト+SKILL.md雛形も作ります。
抽出されたテーブルをExcelに変換する方法を教えてください
Perplexityの回答
CodexでPDFから抽出したテーブルをExcel化するだけなら、基本は「CSVとして出力 → Excelに変換」という流れをスキルに含めるのが扱いやすいです。nanonets+1
1. プロンプトだけでやる場合(CSV→Excel)
すでにテーブルがCSVとして出ている前提で、チャットにこう指示できます。
プロジェクト内の
tables/フォルダにあるすべての.csvを1つのExcelファイルに変換してください。
要件:
- 各CSVをExcelの別シートとしてインポートする(シート名は元のファイル名ベース)。
- 列幅を自動調整し、先頭行をヘッダとしてテーブル書式にする。
- 出力ファイル名は
tables_from_pdf.xlsxとし、保存場所とシート一覧を教えてください。
Codexは内部でCSV読み込み→Excel書き出し用のコードを生成し、指定通り1つのXLSXを作ります。learn.microsoft+1
2. スキルに組み込む場合の SKILL.md 例
PDF→テーブル抽出→Excel変換までを一括処理したいときのイメージです。
---
name: pdf-tables-to-excel
description: 複数ページPDFからテーブルを抽出し、1つのExcelファイルにまとめるスキル
---
# Workflow
1. ユーザーが指定したPDFファイルを開く。
2. すべてのページからテーブルを検出・抽出し、`tables/page-<page>-table-<index>.csv` として保存する。
3. Python と pandas / openpyxl を使って、新しい Excel ファイル `tables_from_pdf.xlsx` を作成する。
4. 各 CSV を別シートとして読み込み、シート名を元ファイル名から設定する。
5. 列幅の自動調整やヘッダ行のテーブル化など、最低限の整形を行う。
6. 完成した Excel ファイルのパスと、作成されたシート名一覧をチャットに表示する。こうしておけば、実行時は次の一言で済みます。
スキル
pdf-tables-to-excelを使って、このPDFから全テーブルを抽出し、tables_from_pdf.xlsxにまとめてください。
3. 1テーブルだけをExcelにしたい場合のプロンプト
添付したPDFから、もっとも大きなテーブルを1つだけ抽出し、その内容を
single_table.xlsxの1枚目のシートとして保存してください。行・列のヘッダを適切に推定し、日本語の列名が壊れないようにしてください。
このように「どのCSV(どのテーブル)を」「どんな構成で」「どんなファイル名で」XLSXにするかを指定すると、Codex側でCSV→Excel変換コードまで自動で組み立ててくれます。funpdf+1
CSVからExcel変換後のグラフ作成例を教えてください
Perplexityの回答
Excelに変換したテーブルからグラフを作る典型パターンを、実務でよく使う3パターンだけに絞って書きます。
1. 基本:折れ線・棒グラフ(時系列)
想定データ
- 列A:日付
- 列B:売上(数値)
Excelでの操作例
- A1:B列のデータ範囲を選択(ヘッダ含む)。w3schools+1
- リボンの「挿入」タブ → 「折れ線グラフ」または「縦棒グラフ」を選択。microsoft+1
- 生成されたグラフのタイトルを「日次売上推移」などに変更。
- 必要に応じて、軸の書式を変更(X軸を日付、Y軸を通貨に)。w3schools+1
Codexへの指示例
tables_from_pdf.xlsxのシートSalesで、列A=日付、列B=売上として折れ線グラフを作成し、「日次売上推移」というタイトルを付けてください。X軸は日付、Y軸は通貨フォーマットにしてください。
2. カテゴリ別の棒グラフ
想定データ
- 列A:カテゴリ(商品名や部門名)
- 列B:値(売上・件数など)
Excelでの操作例
- A1:Bのデータ範囲を選択。excelif+1
- 「挿入」タブ → 「縦棒グラフ」を選択。microsoft+1
- 横軸にカテゴリ名、縦軸に数値が出る。
- 棒ラベルやデータラベルを追加して見やすくする。
Codexへの指示例
シート
CategorySummaryから、列A=カテゴリ、列B=合計値として縦棒グラフを作ってください。
- グラフタイトルは「カテゴリ別合計値」
- 横軸ラベルを45度回転して、文字が重ならないように整形してください。
3. CSV→Excel→ピボットチャート(集計+グラフ)
想定データ
- 列A:日付
- 列B:商品カテゴリ
- 列C:売上
Excelでの操作例
- CSVをExcelテーブルとして取り込み。
- データ範囲を選択 → 挿入 → ピボットテーブル。stackoverflow+1[youtube]
- ピボットテーブルで
- 行:日付(または月)
- 列:カテゴリ
- 値:売上の合計
に設定。support.microsoft+1
- ピボットテーブル上で「ピボットグラフ」を挿入し、複数系列の折れ線や集合縦棒グラフにする。[support.microsoft]
Codexへの指示例
tables_from_pdf.xlsxのシートDataから、
- 行: 日付(または月単位にグループ化)
- 列: 商品カテゴリ
- 値: 売上合計
のピボットテーブルと、そのピボットテーブルを元にした集合縦棒グラフを作成してください。グラフタイトルは「カテゴリ別月次売上」としてください。
この3パターンをベースに、「どのシートのどの列をX軸・Y軸にするか」だけ差し替えれば、ほとんどのCSV→Excel変換後グラフが再利用できます。excelif+3
ローカルファイル処理時のセキュリティ制限を教えてください
Perplexityの回答
Codexアプリでローカルファイルを扱うときは、「サンドボックス(workspace単位)」と「明示的な承認」が大きなガードレールになります。developers.openai+2
サンドボックスの基本
- Codexアプリ/CLIは、OSレベルのサンドボックスで「現在のワークスペース(プロジェクトフォルダ)中心」に権限を絞ります。developers.openai+1
- デフォルトでは
- Git管理されているフォルダ:
Auto(ワークスペース内は読み書き可、怪しい操作は確認) - それ以外:read-only(読み取りのみ)
というモードが推奨されます。onlinetool+1
- Git管理されているフォルダ:
- ワークスペース外(ホームディレクトリ全体など)のファイルを読んだり書き込んだりしようとすると、原則として確認ダイアログや /permissions コマンドでの明示的許可が必要です。developers.openai+1
macOSでの制御
- macOSではSeatbelt+
sandbox-execを使い、選択したサンドボックスモードに応じてアクセス可能ディレクトリを制限します。developers.openai+1 - さらにmacOSの「プライバシーとセキュリティ」で、Codexアプリに付与する「書類フォルダ」「デスクトップ」「フルディスクアクセス」などをOS側で制御できます。codefix+1
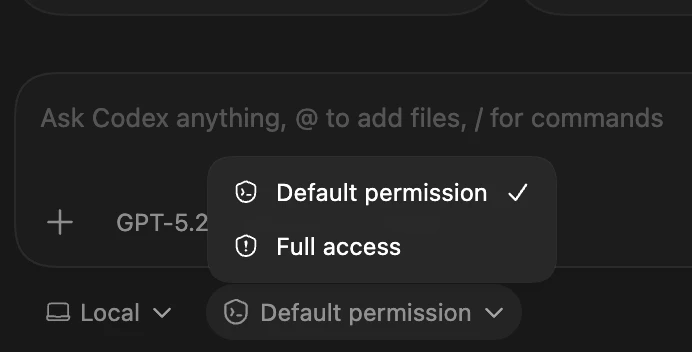
承認ポリシー
--ask-for-approval(またはアプリ設定)で、- 常に承認なし
- 未信頼コマンドだけ確認
- 常に確認
などを選べます。developers.openai+1
- 典型的には「ワークスペース内のファイル編集は自動で許可、外部へのアクセスやネットワークは都度確認」という設定が推奨されています。qiita+1
データがクラウドへ送られる範囲
- Codexは「ローカル優先」で、コードやファイル全体を自動アップロードせず、必要な部分だけをモデルに送る設計になっています。[milvus]
- つまり、大量のソースコードを含むフォルダを開いても、すべてが丸ごとクラウドに同期されるわけではなく、「今のタスクで参照するスニペット」が中心になります。[milvus]
特に気を付けるべき点
- 機密ファイルは、ワークスペースから分離するか、macOS側の権限(ファイル/フォルダアクセス、フルディスクアクセス)でCodexから見えないようにするのが安全です。reddit+1
- 一部の実装では、特定の拡張属性(例:
xattr -w com.openai.codex.skip "true" ファイル名)が付いているファイルはインデックス対象から除外されるため、より細かく制御できます。[codefix]
要するに、「プロジェクトフォルダ単位のサンドボックス+操作ごとの承認+OS側の権限管理」の三段構えで、ローカルファイルへのアクセスが制限されていると考えるとイメージしやすいと思います。openai+3
オートメーションでファイル処理をスケジュールする方法を教えてください
Perplexityの回答
Codexのオートメーションは、「指示+(任意の)スキル」をスケジュール実行する仕組みで、バックグラウンドでファイル処理をさせられます。developers.openai+2
基本の流れ
- プロジェクトを開く
- 処理対象のフォルダ(PDF・Excel・コードなどが入っている場所)をプロジェクトとしてCodexで開きます。[developers.openai]
- オートメーション作成画面を開く
- アプリ左サイドバーの「Automations」ペインから「New automation」を選択。developers.openai+1
- 実行内容(instructions)を書く
- 例(PDF→テーブル→Excel化) このプロジェクト内の新しいPDFをスキャンし、テーブルを抽出してCSV化し、
tables_from_pdf.xlsxに追記してください。
- 例(PDF→テーブル→Excel化) このプロジェクト内の新しいPDFをスキャンし、テーブルを抽出してCSV化し、
- 必要なスキルを指定する
- PDF処理スキルやExcel変換スキルなど、事前に作っておいたスキル名を選択します。macaron+1
- スケジュールを設定する
- 「毎日9時」「毎時」「カスタムcron形式(例:
0 2 * * *で毎日2時)」などを指定できます。macaron+1
- 「毎日9時」「毎時」「カスタムcron形式(例:
- 保存して有効化
- Automationをオンにすると、Codexアプリが起動している間、指定スケジュールで自動実行されます。developers.openai+1
実行と結果の確認
- オートメーション実行結果は、Codexアプリの「Automations」ペイン内の Triage/Inbox に溜まり、差分ファイルやログをそこでレビューできます。developers.openai+1
- 問題ないものはアーカイブ、対応が必要なものだけ開いて修正・マージ、といった運用ができます。[developers.openai]
ファイル処理系の定番スケジュール例
- 毎朝8時:前日フォルダのPDFをテーブル抽出→Excelに集約
- スケジュール:
0 8 * * * - instructions: 昨日更新されたPDFだけを対象にテーブルを抽出し、
daily_tables.xlsxの新しいシートとして追加してください。
- スケジュール:
- 毎時:
incoming/フォルダのCSVをマージしてレポート生成- スケジュール:
0 * * * * - instructions:
incoming/のCSVをすべて読み込み、1つの集計テーブルにマージし、reports/hourly_report.xlsxを更新してください。
- スケジュール:
注意点(制限)
- オートメーションはローカルで動作するため、Macが起動していてCodexアプリが動いている必要があります(クラウドcronではない)。macaron+1
- Gitリポジトリでは、毎回専用の worktree 上で実行されるため、通常の作業ブランチと干渉しにくくなっています。macaron+1
もし「このフォルダのPDFを毎日何時にこう処理したい」といった具体案があれば、そのまま貼れる instructions+スケジュール設定案を日本語で書き起こします。
Codexで画像生成スキルとファイル処理を組み合わせる方法を教えてください
Perplexityの回答
Codexでは、画像生成スキル(DALL·E系やImageGen系)を「普通のファイル処理スキル」と同じ並びで使えるので、ファイル→解析→画像生成→保存まで一連のワークフローにまとめられます。openai+2
1. 代表的な組み合わせパターン
- PDFやMarkdownを読んで、要約からサムネイル画像を自動生成し、/images フォルダに保存。
- ExcelやCSVの統計結果から、グラフ画像+説明用イラストを生成してレポートフォルダに出力。
- プロジェクトのREADMEやドキュメント用に、ロゴ・アイコン・ダイアグラム画像を作るスキルを用意しておき、オートメーションで定期的に再生成。developers.openai+2
2. 画像生成スキルの例(imagegen)
OpenAI公式の imagegen スキルは、テキストプロンプトや既存画像から新しい画像を生成し、プロジェクト内に保存するように定義されています。github+1
例:~/.codex/skills/imagegen/SKILL.md のイメージ
---
name: imagegen
description: プロジェクト用の画像(サムネイル、アイコン、図)を生成・編集するスキル
---
# Workflow
1. ユーザーの指示または別スキルの出力をもとに画像プロンプトを作る。
2. OpenAIの画像生成APIを呼び出し、PNG画像を生成する。
3. 生成画像を `images/` 以下に保存し、ファイルパスをチャットに返す。Codexからは、例えば:
$imagegenスキルを使って、このREADMEの内容を表すサムネイル画像を1枚作成し、images/readme-hero.pngとして保存してください。
のように呼び出します。developers.openai+1
3. ファイル処理スキルと組み合わせる具体例
3-1. PDFレポート → 要約 → サムネイル画像
- PDF処理スキルでレポートを要約する。
- その要約をプロンプトにして、
imagegenスキルでサムネイル生成。 - 画像ファイルをレポートと同じフォルダに保存。
オートメーションの instructions 例:
毎日最新の
report_*.pdfを1件選び、pdf-analyze-reportスキルで要約を作成してください。その要約を元に $imagegen スキルでサムネイル画像を生成し、/reports/images<ファイル名>.png に保存してください。
これを「毎日9時」などでスケジュールすると、レポート+サムネイルが自動で増えていきます。developers.openai+2
3-2. テーブル集計結果からインフォグラフィック
- CSV→Excelスキルで集計して、主要指標(売上TOP3、成長率など)をテキストとして抽出。
- その指標を説明するイラストやインフォグラフィックを
imagegenで生成。 - PowerPoint用/ブログ用フォルダに画像を配置。
指示例:
最新の
monthly_summary.xlsxを読み込み、今月のハイライト(売上TOP3カテゴリと成長率)を文章で要約し、その文章をもとに$imagegenスキルでシンプルな棒グラフ風のインフォグラフィック画像を作成してください。images/monthly-highlight.pngとして保存してください。
4. 既存画像+ファイル処理の組み合わせ
Codexは「画像ファイルを添付した状態でのプロンプト」にも対応しているので、既存画像を読んでファイル処理と組み合わせることもできます。developers.openai+1[youtube]
例:
- スクリーンショット(UI案)を添付 → HTML/CSSを生成 → 同時にそのUIの構造図PNGを imagegen で生成して / design下に保存。[youtube][developers.openai]
- 既存ロゴ画像を添付 → 色違いやバリアントを作るスキルで複数パターン生成し、
assets/に並べる。developers.openai+1
5. オートメーションと合わせるときのポイント
- 画像生成はコストも大きいので、オートメーションでは
- 「新しいファイルが出たときだけ」
- 「週1回だけ」
のようにトリガーや頻度を絞るのがおすすめです。macaron+1
- セキュリティ的には、画像ファイルも他のローカルファイルと同じく、ワークスペース内に限定して読み書きされます
(サンドボックス+承認)。developers.openai+1
もし「具体的に、PDFレポートからサムネイル画像とグラフ付きExcelを毎朝自動で作りたい」といったシナリオがあれば、そのままコピペできる SKILL.md の雛形+オートメーション instructions をセットで書きます。
canvas-designでポスターを作成するプロンプト例
Perplexityの回答
canvas-designは「テーマ+テキスト+スタイル+用途」をしっかり渡すと良いポスターになります。以下、そのまま使えるプロンプト例です。
シンプルな挨拶ポスター
canvas-design スキルを使って、「新年のご挨拶」という日本語テキストを中央に配置したシンプルなポスターを作成してください。
- 出力形式: A4縦向きのPDF
- カラーパレット: 白背景に紅と金をアクセントカラーとして使用
- 雰囲気: 落ち着いた和風、余白多めのミニマルデザイン
- フォント: 読みやすいゴシック体の日本語フォントを想定
イベント告知ポスター
canvas-design スキルで、テック系勉強会「Tokyo AI Meetup」の告知ポスターを作成してください。
- 用途: 屋内掲示用A3縦ポスター(PNG出力)
- レイアウト: 上部にイベントタイトル、中段に日付・場所・参加方法、下部にQRコード用の余白
- カラー: ネイビーブルーをベースに、アクセントカラーにエメラルドグリーン
- スタイル: モダンでフラット、アイコンとシンプルな図形を中心に構成
- 雰囲気: カジュアルだが信頼感のあるトーン
セミナースライド表紙用ポスター
canvas-design スキルを使って、「CodexとAgent Skillsで始める業務自動化」というタイトルのセミナー表紙ポスターを作成してください。
- 出力: 1920×1080のPNG(スライド1枚目として使える比率)
- 要素: タイトル、副題「PDFとExcelをつなぐ実践ワークフロー」、登壇者名「Taro Minato」、日付スペース
- スタイル: ダーク背景に明るいアクセント、グラデーションと線で「フロー」「自動化」をイメージ
- フォント: サンセリフ系で読みやすく、タイトルは太字、大きめ
ブランド準拠の社内ポスター(brand-guidelinesとの併用)
まず brand-guidelines スキルでブランドカラーとタイポグラフィを決めてから、canvas-design スキルで「セキュリティ強化週間」の社内啓発ポスターを作成してください。
- テキスト: 「セキュリティ強化週間」「パスワード使い回し禁止」「不審なメールは報告を」
- 出力: A4縦PDF
- デザイン条件: ブランドカラーと公式フォントを必ず反映し、社内掲示向けにシンプルで視認性の高いレイアウトにすること
抽象アート寄りのビジュアルポスター
canvas-design スキルを使って、「静寂と海」をテーマにした抽象的なアートポスターを作成してください。
- 出力: 高解像度PNG(縦長ポスター想定)
- テキスト: 一切入れない(ビジュアルのみ)
- カラーパレット: 深いブルーとターコイズ、アクセントにごく少量のオレンジ
- スタイル: 幾何学的な形状とグラデーションを組み合わせたミニマルアート
このあたりをベースに、「イベント名」「サイズ」「入れたいテキスト」「色」といったパラメータだけ差し替えると、用途別のcanvas-designプロンプトを量産できます。
Codexアプリを使う場合の料金/プラン
Codexアプリを使う場合の料金/プランについて教えてください
Perplexityの回答
Codexアプリ単体の月額料金はなく、「ChatGPTのサブスクプランに含まれる形」で利用する仕組みになっています。developers.openai+2
個人向けプラン
- ChatGPT Plus
- ChatGPT Pro
- 料金:月 200ドル程度。developers.openai+1
- 内容:Plusの機能に加え、Codexの利用上限(ローカルメッセージ数・クラウドタスクなど)が10倍規模に増加。milvus+2
- 用途:フルタイムで開発に使うヘビーユーザーや、小規模チームなど。
企業・チーム向け
- Business / Team プラン
- Enterprise / Edu
- 料金:カスタム見積もり。milvus+1
- 特徴:利用量に応じた柔軟なクレジット制で、Codexのレート制限も事実上プラン次第でスケールする形。developers.openai+1
レート制限とプロモーション
- 2026年2月のリリース時点では、Plus/Pro/Business/Enterprise/Eduプランに対し、Codexのレート制限が期間限定で2倍になるキャンペーンが案内されています。eesel+1
- 一定期間、ChatGPT Free/GoユーザーもCodexアプリを試用できるが、レート制限は有料プランより厳しめです。eesel+1
API経由で使う場合
- Codexアプリではなく、自作アプリからGPT‑5系やcodex系モデルを叩く場合は「トークン従量課金(入力+出力)」で、モデルごとに単価が設定されています。eesel+1
- 例として、
codex-mini-latestや GPT‑5のAPIは、百万トークンあたり数ドル〜十数ドル程度のレンジで価格が出ています。eesel+1
要するに、MacのCodexアプリを普通に使うだけなら「ChatGPT Plus(月20ドル)」に入っておけば追加料金なしで使え、もっと激しく回したい場合はProやBusinessを検討する、という整理になります。openai+3
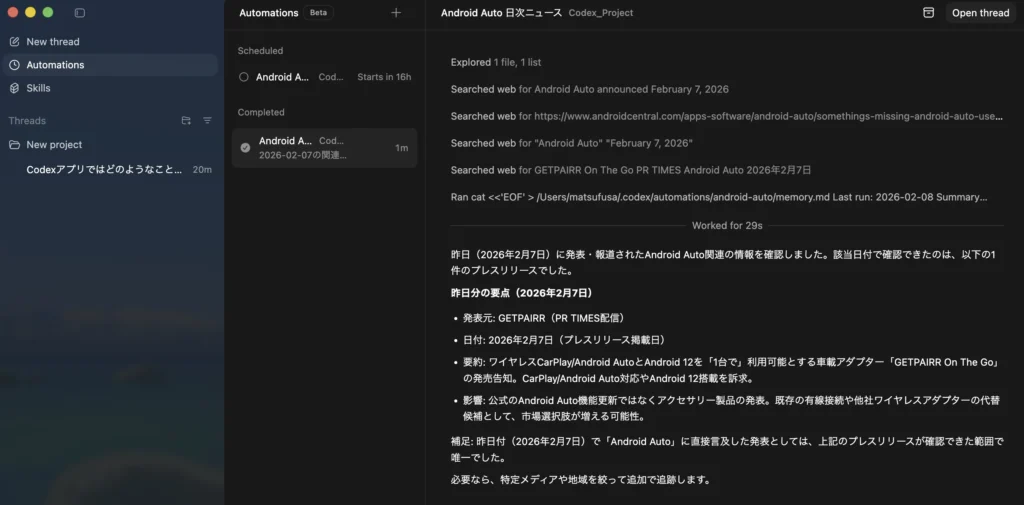
ニュース配信自動化例
ニュース配信の自動化を試した。
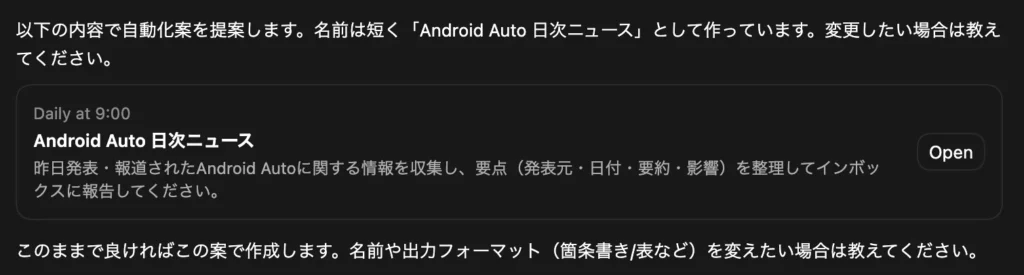
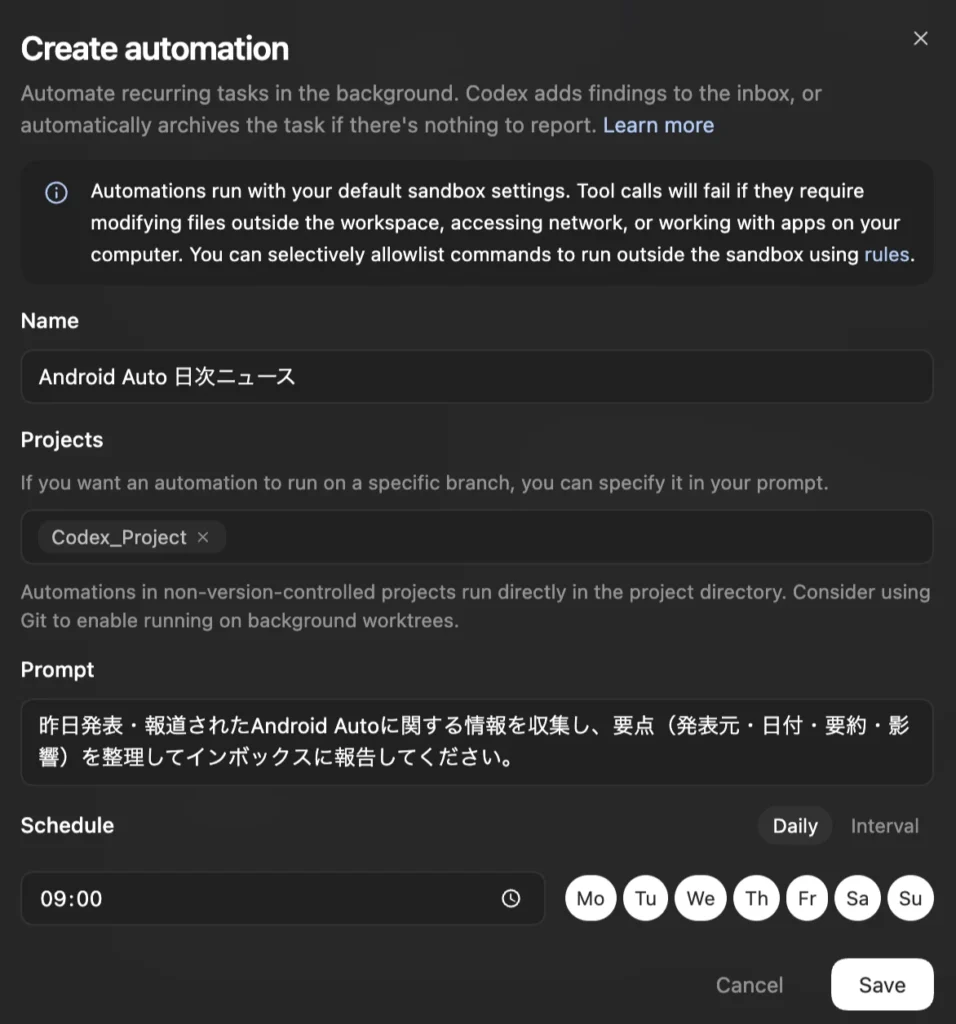
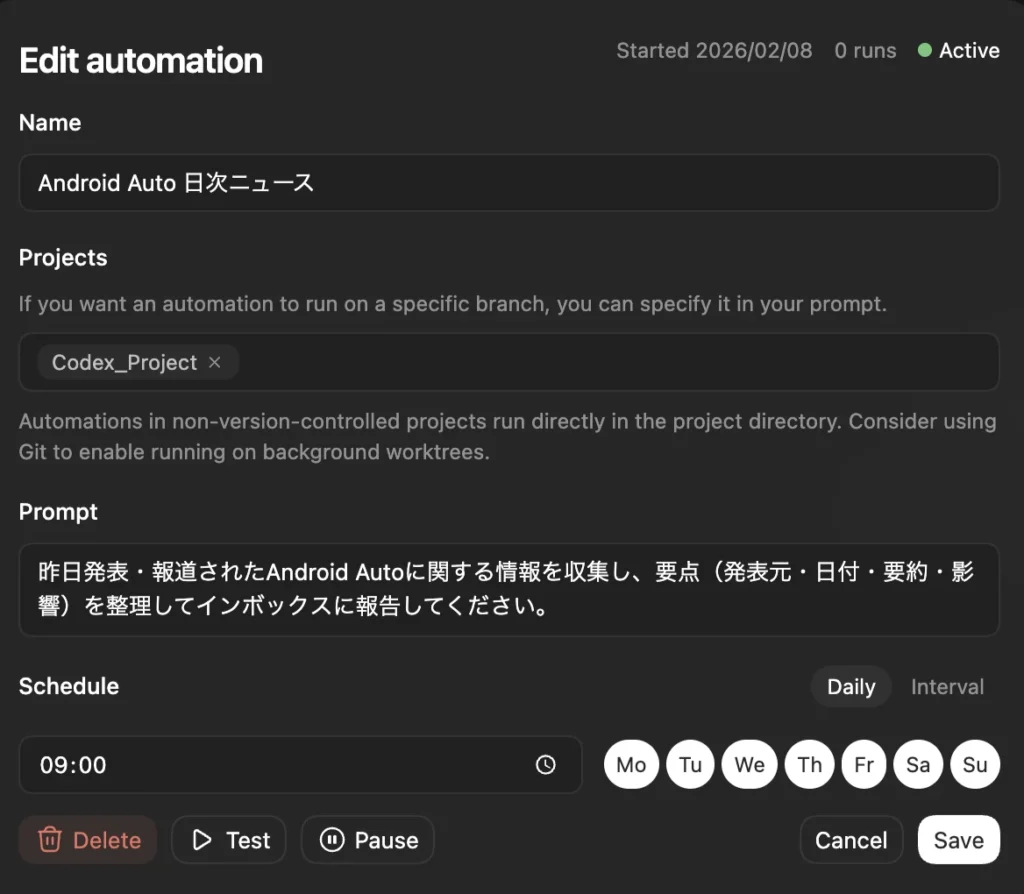
事項結果が保存されるレビューキューはどこにあり、どのようにアクセスできるのですか
Perplexityの回答
Codexアプリの「レビューキュー」は、主にオートメーション(自動実行)の結果やエージェントの変更提案がたまる、専用のインボックス画面にあります。openai+2
どこにあるか
- アプリ左側のサイドバーにある 「Triage」もしくは「Review」セクション がレビューキューです。aitoolsreview+1
- オートメーションが走ると、その結果(見つかった問題、生成された変更など)がこのTriage/Reviewペインに「未読アイテム」として並びます。developers.openai+2
どうアクセスするか
- Codexアプリを開く。
- 左サイドバーの「Automations」の少し下(または近く)にある 「Triage」または「Review」アイコン/タブ をクリック。aitoolsreview+1
- 画面右側に、レビュー待ちの項目一覧が表示されます。
- フィルタで「すべてのオートメーション実行」または「未読のみ」を切り替え可能。[developers.openai]
- 各アイテムをクリックすると、そのタスクに紐づくスレッドやdiffが開き、変更内容を確認・コメント・承認できます。kingy+1
何がたまる場所か
- オートメーションで実行されたファイル処理やコード編集の結果。
- エージェントが提案したコード変更やレビュー結果。
- (Git連携時)worktree上での変更セットや、レビュー対象のdiff。openai+2
つまり、「エージェントやオートメーションが裏でやったことを、人間がまとめて確認するための受け皿」がレビューキューで、左サイドバーの Triage/Review ペインからいつでも開ける、というイメージです。openai+2
automationの設定をCloudで行なって、出先で、そのautomationの結果をスマホで確認することはできますか
Perplexityの回答
現状できることと限界を分けて整理すると、こうなります。developers.openai+3
1. 「Cloud」モードのautomation自体はクラウド上で動かせるか
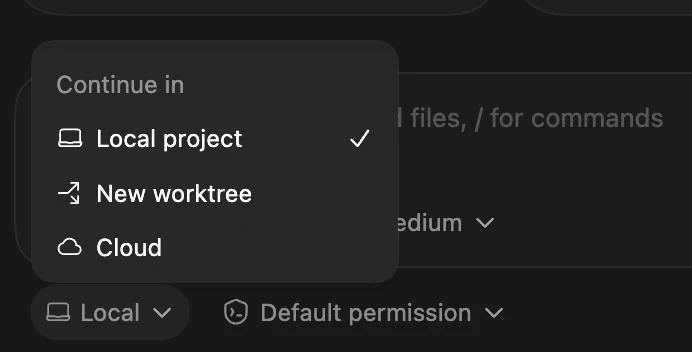
- Codexのスレッドには Local / Worktree / Cloud の3モードがあり、Cloudモードではクラウド環境でエージェントを実行できます。[developers.openai]
- 公式ドキュメントでは、Automationsに対しても「クラウドベースのトリガー対応を拡張中」と明記されており、Macを開いていなくてもバックグラウンドで動かす方向が示されています(開発中の機能扱い)。[openai]
- 一方、現時点のAutomationsの説明では、「Automations run locally in the Codex app. The app needs to be running, and the selected project needs to be available on disk.」とあり、正式にはローカル実行前提です。[developers.openai]
→ つまり、「完全にクラウドだけでスケジュール実行してくれるオートメーション」は、公式にはまだベータ/開発中という位置づけで、通常はMac版Codexアプリが起動している必要があります。openai+1
2. 出先からスマホで結果を確認できるか
公式に想定されているルート
- ChatGPT(Web/モバイルアプリ)のサイドバーから Codex Cloud セッションにアクセスし、進行中のCloudスレッドの状況をスマホで確認する、というワークフローが紹介されています。izanami+1
- Cloudモードのスレッドやレビュー結果がChatGPT側と連携している場合、スマホのブラウザやChatGPTモバイルアプリから、ログやdiffコメントを閲覧・返信することができます。zenn+2
実務でよく使われている迂回ルート
コミュニティでは、次のような形で「結果だけスマホ確認」する構成がよく使われています。dev+1
- SlackやDiscordなどに通知するスキル/MCPを組み込み、
- Automation完了時に Slack チャンネルへ要約・ステータス・リンクをポスト
- スマホではSlackアプリだけ見れば進捗が分かる
- GitHub PRベースで動かし、
- Codexが作ったPRやコメントを、GitHubモバイルアプリで確認する
3. 現時点でできることのまとめ
- Automationの設定そのものは、基本的にデスクトップ版Codexアプリ(あるいはCodex対応のWeb UI)で行います。codecademy+1
- 実行場所は今のところ「ローカルのCodexアプリ上」が公式仕様で、Cloudベースの完全自動実行はロードマップ上の機能です。developers.openai+1
- 結果の確認は、
- Mac上ではCodexアプリの「Triage / Review」ペイン。
- 外出先では、
- CloudモードのスレッドをChatGPTモバイルアプリ/ブラウザから開く
- Slack・GitHubなど外部サービスへの通知を経由してスマホで見る
という形ならすでに実現可能、という状態です。reddit+3
「どういう結果をどこで見たいか」(例:毎朝のバッチ結果をSlackに1行で通知、GitHub PRリンクが欲しい等)を教えてもらえれば、その前提でAutomation instructionsと通知用スキル構成案を具体的に書き出します。
以上、ローカルファイル処理、自動化について調査を行ったが、意外と、できることが多いことが分かった。
例えば、下記のような処理である。
・ChatGPT Atlas(AIブラウザ)と連携して、Codexアプリ内からWeb調査させる、リポジトリの外のドキュメントを参照させる。
・音声書き起こし機能で、会議やレビューの音声から議事録やチケット起こしを自動化できる。
・動画生成AI「Sora」との連携により、プロダクト紹介動画やチュートリアル動画の生成もアプリからトリガーできる。
・macOSの音声入力(ボイスディクテーション)を利用した音声プロンプトにも対応
・OCRを使って表を読み取り、可能な範囲でテーブルとして再構成してください。
・足りない値は、チャット経由で順番に質問する。(日本語で質問しながら入力してください。)
・ピボットテーブルと、そのピボットテーブルを元にした集合縦棒グラフを作成してください。
・画像生成スキル(DALL·E系やImageGen系)を「普通のファイル処理スキル」と同じ並びで使える
スキルを作る場合があるが、PerplexityなどのAIに作ってもらえるようであり、どういう処理をしたいかを具体的に伝えれば、最適解を教えてくれそうである。プロンプトも同様。
自宅で常時立ち上げておく使い方はMacに向いており、私の自宅でも、Windowsデスクトップマシンはほとんど電源OFFだが、Mac miniは常時立ち上げた状態にある。CodexのWindows版も公開予定とのことだが、Windowsデスクトップマシンを常時ONにする気にはなれない。
ニュース配信程度の自動化なら、やはり、Web版のChatGPTを使う方法の方が良いことが確認できた。
Agent Skills
Codexで使用可能なSkillsというのは、Codexだけで使用できるものではなく、オープンで、他社のAIエージェントでも使用できる業界標準のものですか
Perplexityの回答
結論として、CodexのSkillsは「Codex専用の閉じた仕組み」ではなく、Anthropicが提唱した Agent Skills標準 に基づくオープン仕様なので、対応している他社のAIエージェントでもそのまま(か、ほぼそのまま)使える設計です。developers.openai+3
オープン標準かどうか
- Codex公式ドキュメントには「Skills build on the open agent skills standard」と明記されており、フォーマットは公開仕様です。developers.openai+1
- Agent Skills標準は、Anthropicが2025年にオープンスタンダードとして公開したもので、SKILL.md を中心としたフォルダ構成・メタデータ形式が定義されています。ai-souken+3
他社エージェントでの対応状況
- 記事や公式解説では、Claude Code・Cursor・Codex・Gemini CLI など複数ツールがこのAgent Skills標準をサポートし始めているとされています。bishoylabib+3
- 実際に「Claude用に作ったSKILL.mdベースのスキルが、ほぼ設定なしでCodexでも動いた」という検証例も紹介されています。blockchain+1[youtube]
どこまで互換なのか
- ベース構造(
SKILL.mdにname・description・手順を書く、scripts/assets/referencesサブフォルダを持つ、など)は共通なので、ワークフロー知識としての部分はそのまま持ち運び可能です。bishoylabib+1 - 一方で、
- 各プラットフォーム固有のツール呼び出し(例:OpenAI APIの呼び方、MCP/外部ツール名)
agents/openai.yamlのようなプラットフォーム別メタデータ
などは差分が出ることがあり、その部分だけ調整が必要になる場合があります。robert-glaser+2
まとめのイメージ
- 形式としては業界標準(Agent Skills標準)に乗っているオープン仕様。
- Codex、Claude Code、Cursor、Gemini CLIなど複数ベンダーが採用しつつあり、エコシステムとしては「共通スキルを各エージェントで使い回す」方向に進んでいます。zenn+2
- ただし、各ベンダー固有のツール・設定部分だけは、必要に応じて薄くラップ/調整すると考えるのが現実的です。developers.openai+1
AgentSkills.ioの公式リポジトリはどこにありますか
Perplexityの回答
Agent Skills標準の「公式」リポジトリは、Anthropicが公開している次のGitHubリポジトリです。
anthropics/skills(Public repository for Agent Skills)- URL: https://github.com/anthropics/skills[github]
- Agent Skillsの公式サンプルスキル群と、
spec/ディレクトリ内に仕様書(Agent Skills specification)が含まれています。github+1
加えて、標準そのものの仕様・SDKをまとめたリポジトリとして:
agentskills/agentskills(Specification and documentation for Agent Skills)
も案内されています。これらがAgentSkills.ioで定義されているオープン標準の中核リポジトリと考えて問題ありません。agentskills+2
anthropics/skillsリポジトリの人気スキル例
Perplexityの回答
anthropics/skills リポジトリの中で、よく言及される「人気スキル」をいくつかカテゴリ別に挙げます。
Codexでもそのまま参考になります。github+3
ドキュメント系(PDF / Office)
- pdf
- PDFのテキスト・テーブル抽出、PDF生成、結合・分割、フォーム入力など「PDFまわり全部入り」のスキル。skills+2
- docx
- Word文書の作成・編集・書式設定・コメント・差分管理まで含む高度なドキュメントスキル。reddit+2
- xlsx
- スプレッドシートの作成・編集・集計・チャート生成など、Excel系の処理を一通りこなすスキル。anthropic.mintlify+1
- pptx
- プレゼン資料のスライド生成、編集、構成見直しなどを行うスキル。[anthropic.mintlify]
開発・技術系
- webapp-testing
- PlaywrightベースでWebアプリを自動操作し、UIテストやスクリーンショット取得、ログ収集を行うスキル。reddit+1
- mcp-builder
- Model Context Protocol(MCP)サーバーを構築するためのガイド&テンプレ。外部API連携用ツールを作るときのベースとしてよく使われています。ragate+1
クリエイティブ・デザイン系
- canvas-design
- ポスターやバナーなどのビジュアルデザインを
.pngや.pdfで生成するスキル。プロンプトからレイアウトや配色まで含めてデザインしてくれます。skills+1
- ポスターやバナーなどのビジュアルデザインを
- algorithmic-art
- p5.js を使ったジェネレーティブアート用スキル。フローフィールドやパーティクルなど「コードで描くアート」に特化。ragate+1
コミュニケーション・ライティング系
- brand-guidelines
- Anthropic公式ブランドの色やタイポグラフィを適用するスキルですが、企業ブランド適用のテンプレとしてよく参考にされています。reddit+1
- internal-comms
- 社内向けのステータスレポートやニュースレター、FAQなどの定型コミュニケーション文を作るスキル。github+1
メタスキル(スキル作成支援)
- skill-creator
- 「新しいSkillを作りたい」というときに、Q&A形式で要件を聞き取りつつ、正しい SKILL.md を生成してくれるスキル。Anthropicの公式ガイドでも頻繁に推奨されています。zenn+2
Redditの集計や Skills カタログサイトでも、上記の pdf/docx/xlsx/pptx・webapp-testing・canvas-design・brand-guidelines・skill-creator あたりが「コピー数・利用数ともに多い代表例」として挙げられています。skills+2
CopilotやClaudeでのSkills互換性比較
Perplexityの回答
どちらも同じAgent Skills標準に乗っていますが、「読み込み方」と「設定の細かさ」に違いがあります。code.visualstudio+4
共通点(Copilot / Claude / Codex)
SKILL.md+スクリプト類という**共通フォーマット(Agent Skills standard)**を採用しており、基本的なディレクトリ構成は同じです。github+4- Anthropic公式
anthropics/skillsの多くのスキルは、Claude Code・Codex・Copilotでほぼそのまま動かせることが各種記事で確認されています。zenn+3
主な違い(ざっくり比較)
| 観点 | Claude Code | GitHub Copilot(VS Code / CLI) |
|---|---|---|
| フォーマット互換 | Agent Skills標準の「元祖」実装。anthropics/skillsと完全整合。anthropic.mintlify+1 | 同じAgent Skills標準に準拠しており、Claude用スキルをほぼそのまま利用可能。code.visualstudio+2 |
| スキルの読み込み方 | 起動時に全スキルのメタデータを把握し、その上で内部ロジックで選択。[tech-lab.sios] | 事前フィルタリングで候補を絞り、descriptionの関連度に基づいて読み込む(確率的)。code.visualstudio+2 |
| 発火しやすさ | descriptionが多少ラフでも適切なスキルを拾いやすい。[tech-lab.sios] | descriptionが弱いと「スキルが発火しない」ケースが出やすい。キーワードを明確に書く必要あり。tech-lab.sios+1 |
| 配置場所 | 例:~/.claude/skills など。エディタやCLIから共通利用。anthropic.mintlify+1 | VS Codeのskillsフォルダやリポジトリ直下など、Copilot設定で指定した場所。code.visualstudio+1 |
| 対応エージェント | Claude Code, Claude Desktop, 一部サードパーティエージェント。anthropic.mintlify+1 | Copilot coding agent, Copilot CLI, VS CodeのAgent Modeなど複数クライアント。code.visualstudio+2 |
Codexも同じ標準を採用しており、実態は「Claude寄りの挙動(すべて把握してから選択)」に近いと解説されています。zenn+3
実務上の「互換性のコツ」
- SKILL.mdの書き方を素直に標準に合わせる
nameはシンプルなスラッグ、descriptionは「何を、どんなツールで、どんな場面で使うか」を1〜3文で具体的に。agentskills+4
- Copilotではdescriptionを厚めに
- Copilot側はdescriptionベースでスキル候補を絞るため、「PDF」「テーブル抽出」「Excel」「レポート」など、実際の使用キーワードをすべて含めると発火率が上がります。tech-lab.sios+2
- プラットフォーム依存部分は薄いラッパーに分離
- 例えば
openai-apiやclaude-apiの呼び出し、MCPサーバー名などはagents/openai.yaml/agents/github.yamlのように分けるパターンが紹介されています。developers.openai+2
- 例えば
まとめのイメージ
- 構造・フォーマットはほぼ完全互換なので、1つのSkillsカタログをClaude Code・Copilot・Codexで共有することは現実的です。github+3
- 差が出るのは「どのスキルをいつ起動するか」という選択ロジックで、特にCopilotはdescriptionや設定次第で発火しないことがある点だけ注意しておくとよいです。code.visualstudio+3
Agent Skills standardのSKILL.mdの具体的な書き方を教えてください
Perplexityの回答
Agent Skills標準のSKILL.mdは、「YAMLフロントマター+Markdown本文」の2部構成で書きます。agentskills+3
1. 最小構成の例
---
name: pdf-tables-to-excel
description: PDFからテーブルを抽出し、CSVとExcelにまとめる。PDFレポート処理や帳票のデータ化に使う。
---
# PDFテーブル抽出&Excel変換スキル
## このスキルでやること
1. 指定されたPDFファイル(またはプロジェクト内のPDF)を開く。
2. すべてのページからテーブルを検出・抽出する。
3. テーブルを `tables/page-<page>-table-<index>.csv` として保存する。
4. すべてのCSVを読み込み、1つのExcelファイル `tables_from_pdf.xlsx` にまとめる。
5. 作成したファイルの一覧と、ページごとのテーブル数のサマリをエージェントの出力として返す。
## 実行時のヒント
- PDFが複数ある場合は、ユーザーに対象ファイル名を確認してから処理する。
- スキャンPDFの場合はOCRを行い、テーブル構造を可能な範囲で再構成する。
- エラーが発生したら、どのページで失敗したかをメッセージに含める。これで「最低限必要なフィールド+実行手順」が揃ったSKILL.mdになります。agentskills+3
2. フロントマター(YAML)の書き方
先頭は必ず --- で始まり、--- で閉じます。deepwiki+2
必須フィールド
name- スキルID。ディレクトリ名と同じ、小文字+数字+ハイフンのみ(例:
pdf-tables-to-excel)。[deepwiki]
- スキルID。ディレクトリ名と同じ、小文字+数字+ハイフンのみ(例:
description- スキルが何をするか・いつ使うべきかを1〜数文で書く。エージェントが「どの場面で呼ぶか」を判断する材料。deepwiki+1
任意フィールド(よく使うもの)
---
name: pdf-tables-to-excel
description: PDFからテーブルを抽出し、CSVとExcelにまとめる。PDF帳票のデータ化に使用。
license: MIT
allowed-tools:
- python
- shell
metadata:
category: pdf-processing
author: your-name
created: 2026-02-09
---
license:スキルの配布ライセンス。deepwiki+1allowed-tools:このスキル内で使ってよいツール名のホワイトリスト(例:python,bash,openai-api)。deepwiki+1metadata:自由形式の追加情報(カテゴリ、作者、バージョンなど)。deepwiki+1
3. Markdown本文の書き方
YAMLの後ろは普通のMarkdownで、エージェントにやってほしい手順・ルールを自然文で書きます。agentskills+1
よく使われる構成:
# スキルのタイトル
## 目的
このスキルは、◯◯をしたいときに使う。たとえば…
## 前提条件
- 入力ファイルの場所や形式
- 必要な外部サービスや認証
- 使ってよいツール・ライブラリ
## ワークフロー
1. 何を最初に確認するか
2. どの順番で処理するか
3. 失敗時・例外時にどう振る舞うか
## 出力フォーマット
- エージェントの最終出力はどういう形式か(例:Markdown表、JSON、ファイルパスの一覧)
- ユーザーに必ず伝えるべき情報Agent Skills標準では「フロントマターは短く、本文に詳細を書く」「必要に応じて references/ など別ファイルに分割」といったプラクティスが推奨されています。agent-skills+2
4. ディレクトリ構成の例
スキルはフォルダ単位で管理され、SKILL.md が必須、それ以外は任意です。developers.openai+2
pdf-tables-to-excel/
SKILL.md # 必須:メタデータ+手順
scripts/ # 任意:Pythonやシェルなど実行スクリプト
extract_tables.py
references/ # 任意:仕様書・APIドキュメントなど
pdf_table_notes.md
assets/ # 任意:テンプレート、サンプルファイル
example.pdf
agents/
openai.yaml # 任意:Codex用の見た目や依存関係設定
Codexの場合は、このフォルダを ~/.codex/skills/(または設定で指定したskillsディレクトリ)配下に置けば認識されます。developers.openai+1
5. 最小ひな形(そのまま流用用)
新しくSkillを作るときの「白紙テンプレ」としては、次のくらいが扱いやすいはずです。
---
name: my-skill-name
description: 何をするスキルか、どんな状況で使うべきかを1〜2文で書く。
---
# My Skill Title
## 目的
このスキルは、◯◯を行うために使う。主なユースケースは…
## 前提条件
- 入力ファイルや環境の前提
- 使ってよいツールやAPI
## ワークフロー
1. ◯◯を確認する。
2. ××を実行する。
3. 結果を△△の形式に整形する。
## 出力
- ユーザーへの最終出力形式
- 必要なら、生成・更新されるファイルパスも明示する。ここに、いま検討されているPDF/Excel自動化の手順をそのまま書き込めば、CodexでもClaude Codeでも動かしやすい「Agent Skills標準準拠のSKILL.md」になります。agentskills+3
参考リンク
Agent Skills Overview https://agentskills.io/home